本文面向需要将大量PDF文档转换为HTML网页文件的办公场景,介绍如何使用核烁文档批量处理工具一次性导入多个PDF,并批量生成对应的.html文件。文章结合处理前、处理后效果和软件界面步骤,说明从选择PDF转HTML功能、添加文件、确认列表到设置保存位置并开始处理的完整流程,帮助用户减少重复操作,提高文档发布和归档效率。
在日常办公、资料归档、网页内容发布、知识库整理或系统资料迁移过程中,经常会遇到这样的问题:手里有很多PDF文件,例如产品说明书、合同模板、培训资料、制度文件、报表导出件等,需要把它们转换成HTML网页文件,方便在浏览器中打开、上传到网站、嵌入内部系统,或交给开发、运营、内容团队继续处理。如果一个PDF一个PDF地手动转换,不仅耗时,而且容易漏掉文件、命名混乱,后续还要反复核对结果。
本文要解决的就是“如何批量将很多PDF转换为HTML网页文件”的问题。借助办公软件“核烁文档批量处理工具”中的PDF转换功能,可以把多个.pdf文件一次性加入任务列表,统一转换为.html网页文件。整个流程的核心价值在于批量处理文件,减少重复劳动,让原本需要多次点击、反复选择文件的操作,集中在一个任务中完成。
适用场景:哪些情况下需要批量PDF转HTML网页文件
PDF格式适合阅读、打印和保持版式,但在网页展示、内容检索、系统集成方面,HTML网页文件往往更灵活。将PDF批量转换为HTML后,文件可以直接用浏览器打开,也更适合用于网站资料页、企业内网文档页、帮助中心页面、在线说明文档等场景。
常见使用场景包括:第一,企业有一批PDF版产品资料,需要转换成HTML页面后上传到网站或资料库;第二,培训部门有大量PDF课件,需要生成网页文件,方便员工在线查看;第三,档案或行政人员需要把扫描整理后的PDF资料转成可在浏览器中查看的网页格式;第四,内容运营人员需要把PDF资料作为网页内容的基础素材,再进行后续编辑和发布;第五,研发或信息化团队需要将PDF文件批量转为HTML,以便集成到系统页面、知识库或帮助文档平台中。
对于文件数量较少的情况,手动转换还能勉强应付;但当PDF数量达到几十个、几百个时,批量处理就非常必要。使用核烁文档批量处理工具,可以在一个界面中集中导入PDF文件,并按照任务流程统一处理,避免频繁打开不同工具、重复选择保存路径和重复确认转换结果。
效果预览:处理前是多个PDF文件,处理后生成HTML网页文件
在处理前,文件夹中存放的是多个PDF文档。从截图可以看到,示例文件包括1.pdf、2.pdf、3.pdf、4.pdf。这些文件都是待转换的源文件,扩展名为.pdf,通常需要使用PDF阅读器打开。

经过批量PDF转HTML处理后,同一批文件会转换为对应的HTML网页文件。处理后的结果示例为1.html、2.html、3.html、4.html。文件图标显示为浏览器相关图标,说明这些.html文件可以直接通过浏览器打开查看。转换后文件名与原PDF文件名保持对应关系,这样后续查找和核对会更直观。

从处理前后对比可以看出,核心变化是文件格式从PDF变为HTML网页文件:1.pdf对应生成1.html,2.pdf对应生成2.html,依次类推。这种一一对应的批量转换方式,特别适合需要保留原始文件命名逻辑的办公流程,例如按编号、按日期、按项目名称整理的文档资料。
使用的软件:核烁文档批量处理工具的PDF批量转换能力
本文演示的软件为“核烁文档批量处理工具”。从界面可以看到,它是一款面向办公文档批量处理的软件,左侧导航包含首页、任务流、所有工具、文件名称、文件夹名称、文件整理、Word工具、Excel工具、PowerPoint工具、PDF工具、文本工具、图片工具、视频工具、音频工具、更多工具等分类。
这类工具的定位并不是单纯打开某一个文档,而是围绕“批量处理文件”展开。对于PDF相关工作,它提供了多种PDF处理入口,例如PDF转换为Word、PDF转换为PowerPoint、PDF转换为TXT、PDF转换为Excel、PDF转换为Epub、PDF转换为XML、PDF转换为HTML网页等。本文重点使用的是“PDF转换为HTML网页”功能。
在办公场景中,批量处理工具的优势非常明显:用户不需要反复打开多个PDF,也不需要一个文件转换一次。只要把待处理文件一次性导入任务列表,再按步骤设置保存位置并开始处理,就可以完成一批文件的格式转换。对于需要长期处理大量文档的用户来说,这种流程可以显著减少重复劳动。
操作步骤一:进入PDF工具,选择“PDF转换为HTML网页”功能
打开核烁文档批量处理工具后,先在左侧功能分类中选择“PDF工具”。进入PDF工具列表后,可以看到多个PDF处理卡片。截图中展示的功能列表包含“PDF转换为Word”“PDF转换为PowerPoint”“PDF转换为XPS”“PDF转换为TXT”“PDF转换为Svg图片”“PDF转换为JPG图片”“PDF转换为MP4视频”“PDF转换为Excel”“PDF转换为Epub”“PDF转换为XML”“PDF转换为HTML网页”“PDF转换为OFD”等。
本次要把PDF文件转换为HTML网页文件,因此需要点击编号为23的“PDF转换为HTML网页”。截图中该功能卡片处于高亮状态,并有红色箭头指向,提示用户选择该入口。功能说明为“批量将PDF文件转换为HTML网页”,这与本文的需求完全对应。
这一步的操作目的,是从众多PDF工具中找到正确的转换功能。预期结果是进入“PDF转换为HTML网页”的任务页面。选择正确功能非常重要,因为PDF可以转换为多种格式,例如Word文档、Excel表格、JPG图片、XML文件、Epub电子书等,如果误选其他功能,最终输出格式就不会是.html网页文件。
操作步骤二:添加需要转换的PDF文件
进入“PDF转换为HTML网页”页面后,界面顶部显示当前功能名称,左侧有“返回到主面板”按钮,右侧有“添加文件”“从文件夹中导入文件”“清空”“更多”等操作按钮。中间区域是任务列表,用于显示本次需要处理的PDF记录。
如果只需要添加几个指定PDF,可以点击“添加文件”,从本地文件夹中选择目标文件。如果待转换的PDF集中放在同一个文件夹中,也可以使用“从文件夹中导入文件”,这样更适合一次性导入大量文档。截图中红色箭头指向“添加文件”区域,强调了导入文件是批量转换流程中的关键步骤。
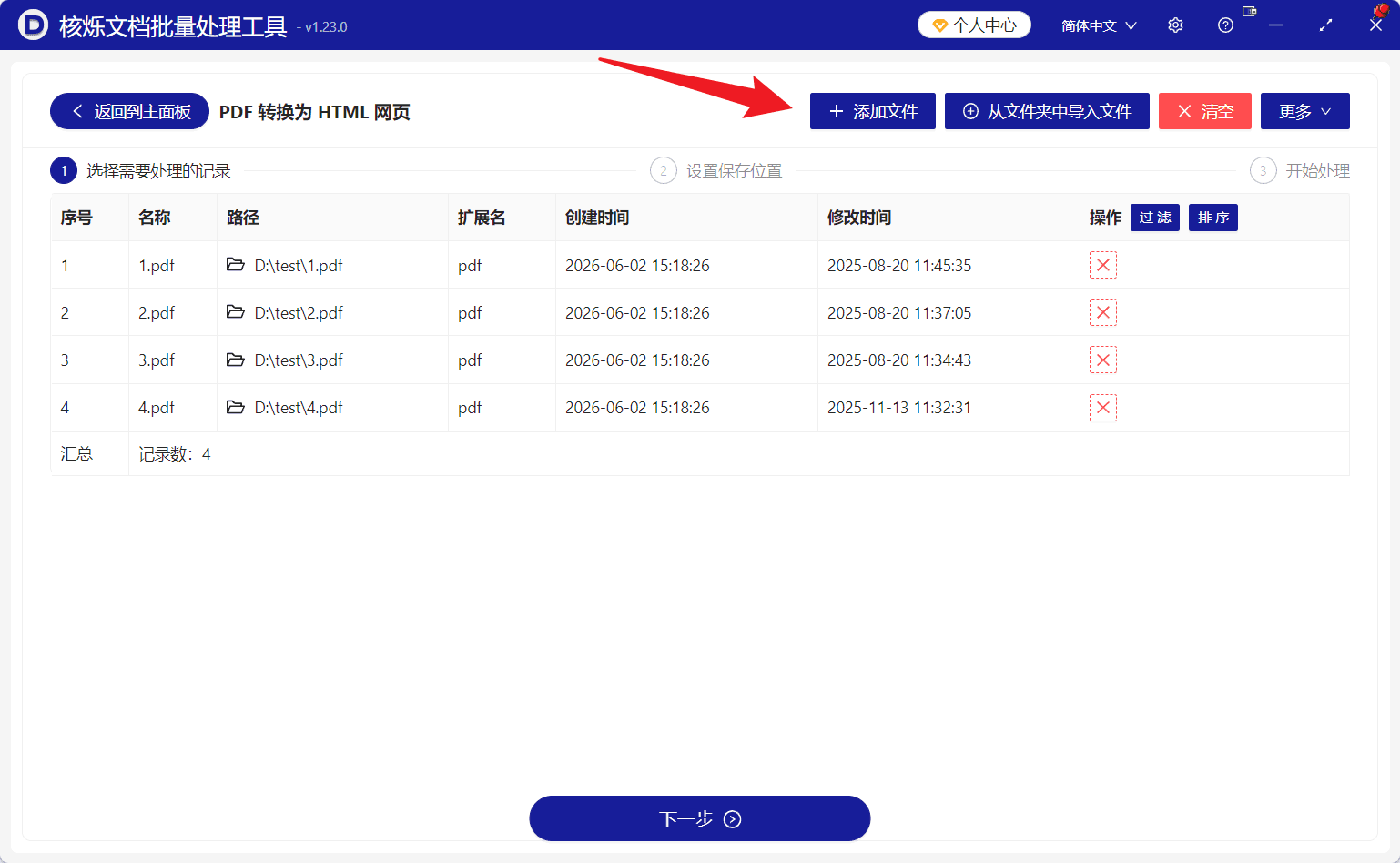
从截图中的任务列表可以看到,已经导入了4个PDF文件,分别是1.pdf、2.pdf、3.pdf、4.pdf。列表列出了序号、名称、路径、扩展名、创建时间、修改时间和操作等信息。路径示例为D:\test\1.pdf、D:\test\2.pdf、D:\test\3.pdf、D:\test\4.pdf,扩展名均为pdf。底部汇总区域显示“记录数:4”,说明当前任务中共有4条待处理记录。
这一步的操作目的,是把所有需要转换为HTML的PDF源文件加入同一个批处理任务。预期结果是文件列表中出现所有待处理PDF,并且记录数量与实际要转换的文件数量一致。开始转换之前,建议先检查列表中的名称和路径,确认没有选错文件、没有漏选文件。
操作步骤三:核对任务列表,必要时删除、过滤或排序
在文件导入后,不建议马上进入下一步,而是先核对任务列表。截图中每条记录右侧都有操作区域,并显示删除图标。如果发现某个PDF不需要转换,可以通过对应记录的操作入口将其移除。界面上方还可以看到“清空”按钮,如果导入了错误的一批文件,可以清空当前列表后重新添加。
表格右侧还显示“过滤”“排序”按钮。根据截图可见,它们位于任务列表的操作区域中,通常用于帮助用户在记录较多时整理和查找文件。对于只有几个文件的任务,手动核对即可;如果批量导入了大量PDF,先通过列表信息检查扩展名、路径和文件名,会更稳妥。
这一步的操作目的,是确保待处理文件准确无误。预期结果是列表中只保留需要转换的PDF文件,并且文件数量正确。例如本例中,待处理记录数为4,对应处理前文件夹中的1.pdf、2.pdf、3.pdf、4.pdf。这样后续生成的HTML结果也更容易核对。
操作步骤四:点击“下一步”,设置HTML文件保存位置
文件列表确认无误后,可以点击页面底部的“下一步”。从任务流程条可以看到,当前页面属于第1步“选择需要处理的记录”,后续还有第2步“设置保存位置”和第3步“开始处理”。因此,点击“下一步”后,软件会进入保存位置设置环节。
设置保存位置的目的,是指定批量转换后生成的HTML网页文件保存到哪里。为了便于管理,建议选择一个单独的输出文件夹,例如“PDF转HTML结果”“网页文件输出”或项目对应的资料目录。这样转换完成后,不会与原PDF文件混在一起,也方便统一检查1.html、2.html、3.html、4.html等结果文件。
虽然截图中没有展开保存位置页面的具体细节,但流程条明确显示了“设置保存位置”步骤。因此可以合理判断,在正式处理前,用户需要根据软件提示完成输出目录设置。预期结果是软件记录好HTML文件的保存位置,并允许进入开始处理阶段。
操作步骤五:开始批量处理,等待PDF转换为HTML完成
完成保存位置设置后,继续按照界面流程进入第3步“开始处理”。这一步的核心任务是让软件自动执行PDF到HTML的格式转换。用户不需要逐个打开PDF,也不需要逐个另存为网页文件,只需要确认任务并启动处理即可。
批量转换过程中,软件会按照任务列表中的记录处理文件。以本例为例,列表中有4个PDF文件,转换完成后会得到4个对应的HTML文件,即1.html、2.html、3.html、4.html。处理完成后,可以打开输出目录检查结果,并使用浏览器打开HTML文件进行确认。
这一步的预期结果,是所有选中的PDF均生成对应的.html网页文件。如果文件数量较多,建议处理完成后抽查部分结果,确认网页能够正常打开,并核对文件名是否与源PDF对应。
常见问题和注意事项
1. PDF转HTML后文件名会不会改变?
从示例效果看,转换后的HTML文件与原PDF文件名保持对应关系,例如1.pdf转换为1.html,2.pdf转换为2.html。这种命名方式便于用户快速判断每个网页文件对应哪一个PDF源文件。
2. 可以一次导入整个文件夹里的PDF吗?
截图中可以看到“从文件夹中导入文件”按钮。如果待转换PDF集中在同一个文件夹中,使用该入口通常比逐个添加文件更高效,适合批量处理大量PDF文档。
3. 导入文件后发现选错了怎么办?
可以在任务列表中通过单条记录右侧的操作图标移除不需要的文件,也可以使用顶部的“清空”按钮清除当前列表后重新导入。开始处理前先核对文件列表,可以减少返工。
4. 为什么要单独设置保存位置?
批量转换会生成多个HTML文件。如果保存位置没有规划好,结果文件可能与原始PDF或其他资料混在一起,后期查找不方便。建议单独建立输出文件夹,便于管理、备份和上传。
5. HTML文件如何打开?
从处理后截图可以看到,HTML文件显示为浏览器相关图标。通常情况下,双击.html文件即可使用默认浏览器打开。也可以右键选择浏览器打开,用于检查转换效果。
6. 批量PDF转HTML适合替代人工复制内容吗?
如果只是少量文字复制,人工操作也可以完成;但当PDF数量较多,且需要形成独立网页文件时,批量转换更适合。它能减少重复点击、复制、粘贴和另存为的过程,降低遗漏概率。
总结:用批量处理方式让PDF转HTML更高效
批量将PDF转换为HTML网页文件,本质上是把重复的格式转换工作交给办公软件自动完成。本文演示的流程非常清晰:先准备多个PDF文件,再在核烁文档批量处理工具中进入PDF工具,选择“PDF转换为HTML网页”,添加文件或从文件夹导入文件,核对任务列表,点击下一步设置保存位置,最后开始处理并获得对应的.html网页文件。
对于经常处理PDF资料的办公人员来说,这种批量转换方式可以显著节省时间。无论是4个文件,还是更多PDF文档,只要流程一致,都可以通过批处理减少机械重复操作。建议在实际使用时,先把待转换PDF集中整理到一个文件夹中,再使用“从文件夹中导入文件”或“添加文件”建立任务,转换完成后统一检查输出的HTML文件。这样既能提高效率,也能让文档转换结果更加规范、易管理。