PDF归档时,文件名是否清晰直接影响后续查找效率。对于首页第一行就是标题的PDF,可以使用批量处理工具自动读取该文字并设置为文件名。本文以核烁文档批量处理工具为例,展示从处理前的数字文件名,到处理后的标题文件名的完整过程,并详细说明如何进入“使用文件内容重命名PDF文件”、导入文件、选择第一行文本、设置截取长度和覆盖文件名,帮助用户快速整理合同、资料、课件等PDF文档。
在合同归档、课程资料整理、项目报告汇总等办公场景中,PDF文件名是否规范非常重要。一个清晰的文件名可以让你在文件夹中快速识别内容,也能让搜索更准确;而一个只有数字或随机字符的文件名,会让后续查找变得困难。
很多PDF其实已经在首页顶部写好了标题,例如合同名称、资料名称、报告标题或课程主题。问题在于,这些标题在PDF内部,文件名却仍然是1.pdf、2.pdf、3.pdf。如果手动打开每个PDF再复制标题改名,工作量会很大。本文将介绍如何用核烁文档批量处理工具,把PDF首页的第一行文字批量设置为文件名,从而快速完成PDF归档整理。
适用场景:需要按PDF内容建立文件名的办公任务
按PDF首页标题批量重命名,适合用于文件本身内容有规律,但外部文件名不规范的情况。特别是当PDF第一页第一行就是标题时,使用“第一行文本”作为重命名来源,可以获得比较理想的效果。
你可以在以下场景中使用这种方法:
- 合同文件归档:合同PDF首页通常有合同标题或协议名称,批量提取后可直接作为文件名。
- 培训课件整理:课件首页常见课程名称、章节标题,适合按标题命名。
- 项目报告管理:报告第一页通常有报告名称,按标题重命名后更便于项目资料归档。
- 英文资料或说明书整理:例如截图中的英文学习资料,文件名可由首页文字自动生成。
- 扫描或导出文件整理:系统导出后的PDF可能只保留序号,但正文中包含可用标题。
核烁文档批量处理工具是一款办公场景下的批量文档处理软件,核心价值是帮助用户批量处理文件、减少重复劳动。对于“批量修改PDF文件名”这类高频但重复的任务,它可以把大量手动步骤变成规则化处理。
效果预览:从数字文件名变成标题文件名
处理前:文件名无法体现内容
处理前的文件夹中,PDF名称分别是1.pdf、2.pdf、3.pdf、4.pdf。这样的文件名没有任何业务含义,也无法看出是合同、学习资料还是报告。文件数量越多,查找成本越高。

打开其中一个PDF,可以看到页面靠下位置有一行醒目的文字“Learn English in an easy,”。截图用红框标出了这行文字,它就是后续用于生成文件名的内容来源之一。
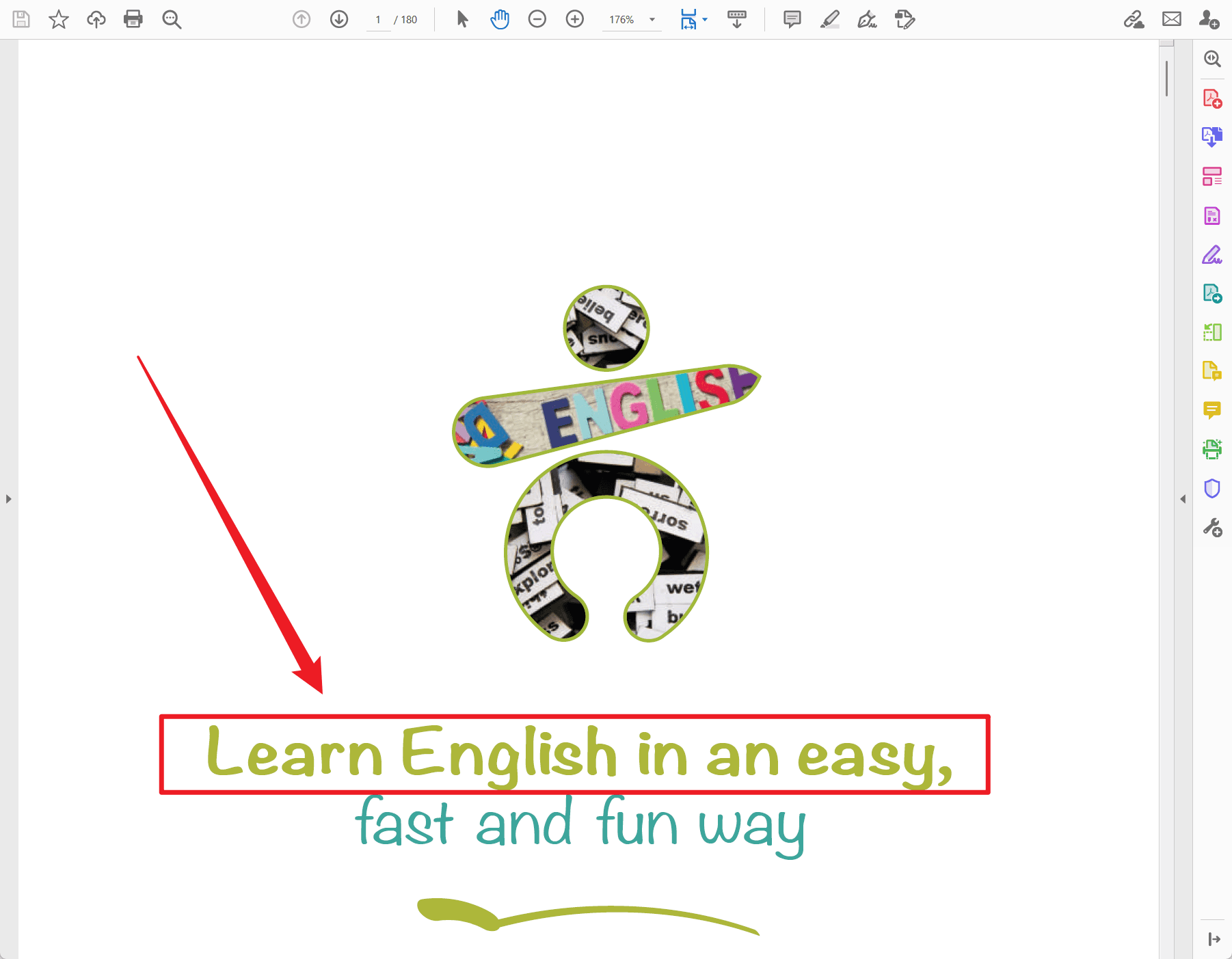
在真实办公中,这一行可能是“采购合同”“员工培训手册”“年度审计报告”“项目验收说明”等。只要它是你希望出现在文件名中的内容,就可以考虑使用第一行文字重命名。
处理后:文件名可读、可搜索、可归档
处理完成后,文件名已经根据PDF内容发生变化。截图中可以看到,原本的数字文件名被替换成了“Learn English in an easy.pdf”“Learning tips.pdf”“NASA Office of Inspector General.pdf”“Sample Contract.pdf”等更具识别度的名称。

这种命名方式更适合日常管理。你可以直接从文件名判断内容,也可以通过关键词搜索文件。例如搜索“Contract”即可快速定位合同类PDF,搜索“English”即可找到英文学习资料。
操作步骤:把PDF第一行文字批量设置为文件名
步骤一:打开软件并进入文件名称处理模块
打开核烁文档批量处理工具后,先观察左侧导航栏。截图中可以看到,软件按办公任务类型划分了多个模块,包括首页、任务流、所有工具、文件名称、文件夹名称、文件整理、Word工具、Excel工具、PowerPoint工具、PDF工具等。
本次目标是重命名PDF文件,所以选择左侧的“文件名称”。在右侧功能卡片中找到“使用文件内容重命名 PDF 文件”。该功能卡片说明为批量将PDF文件内容中的某些文本作为文件名,非常适合本次任务。
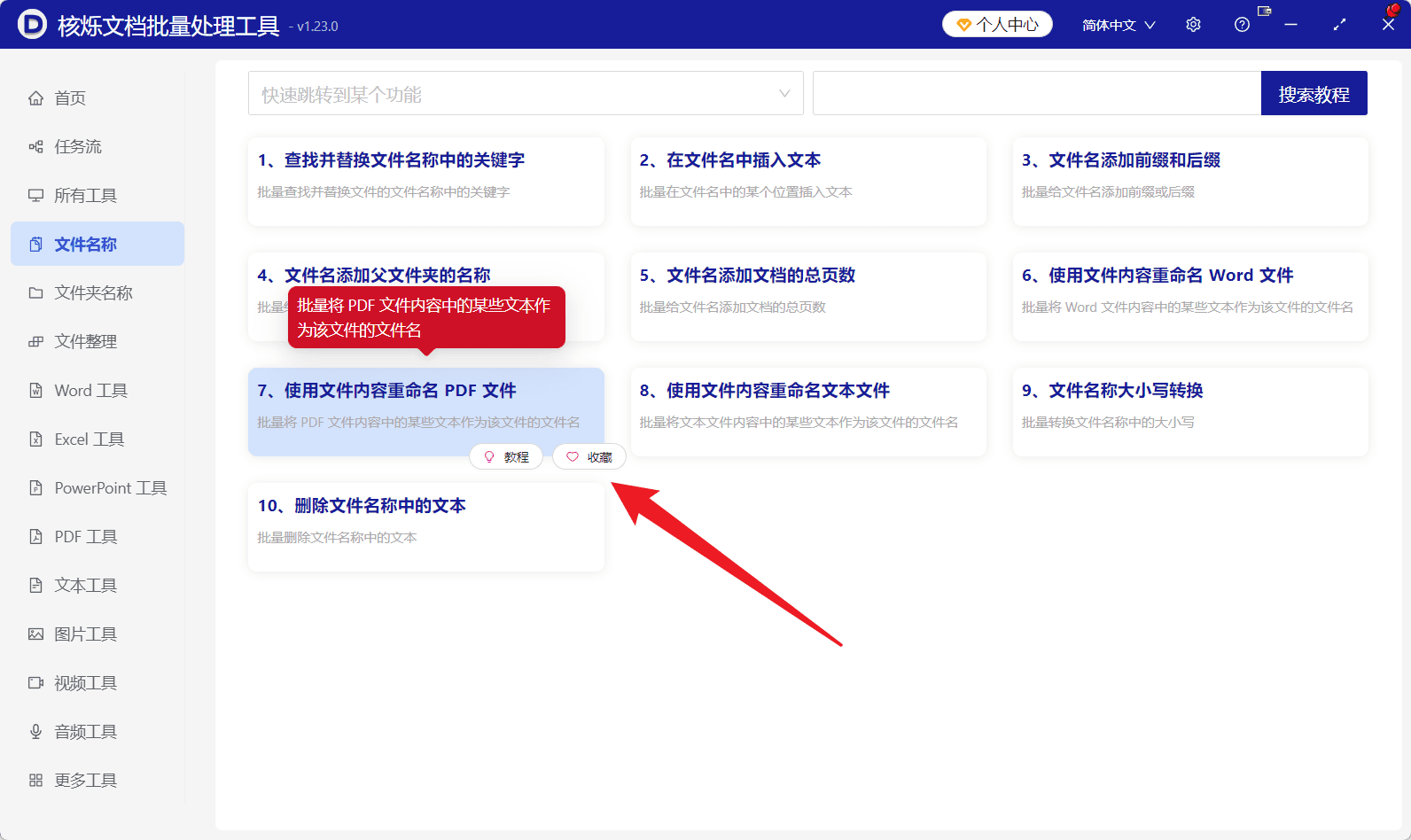
点击该功能后,进入具体的批量处理页面。选对入口非常关键,因为我们不是给文件名简单加前缀,也不是替换文件名里的某个关键词,而是要读取PDF内容来生成文件名。
步骤二:添加PDF文件或从文件夹导入
进入“使用文件内容重命名 PDF 文件”页面后,首先处于流程的第1步“选择需要处理的记录”。页面右上方有“添加文件”“从文件夹中导入文件”“清空”“更多”等按钮。
如果你只处理几份PDF,可以使用“添加文件”;如果要处理一个文件夹里的全部PDF,使用“从文件夹中导入文件”更节省时间。导入后,文件列表会显示每个PDF的名称、路径、扩展名、创建时间和修改时间。
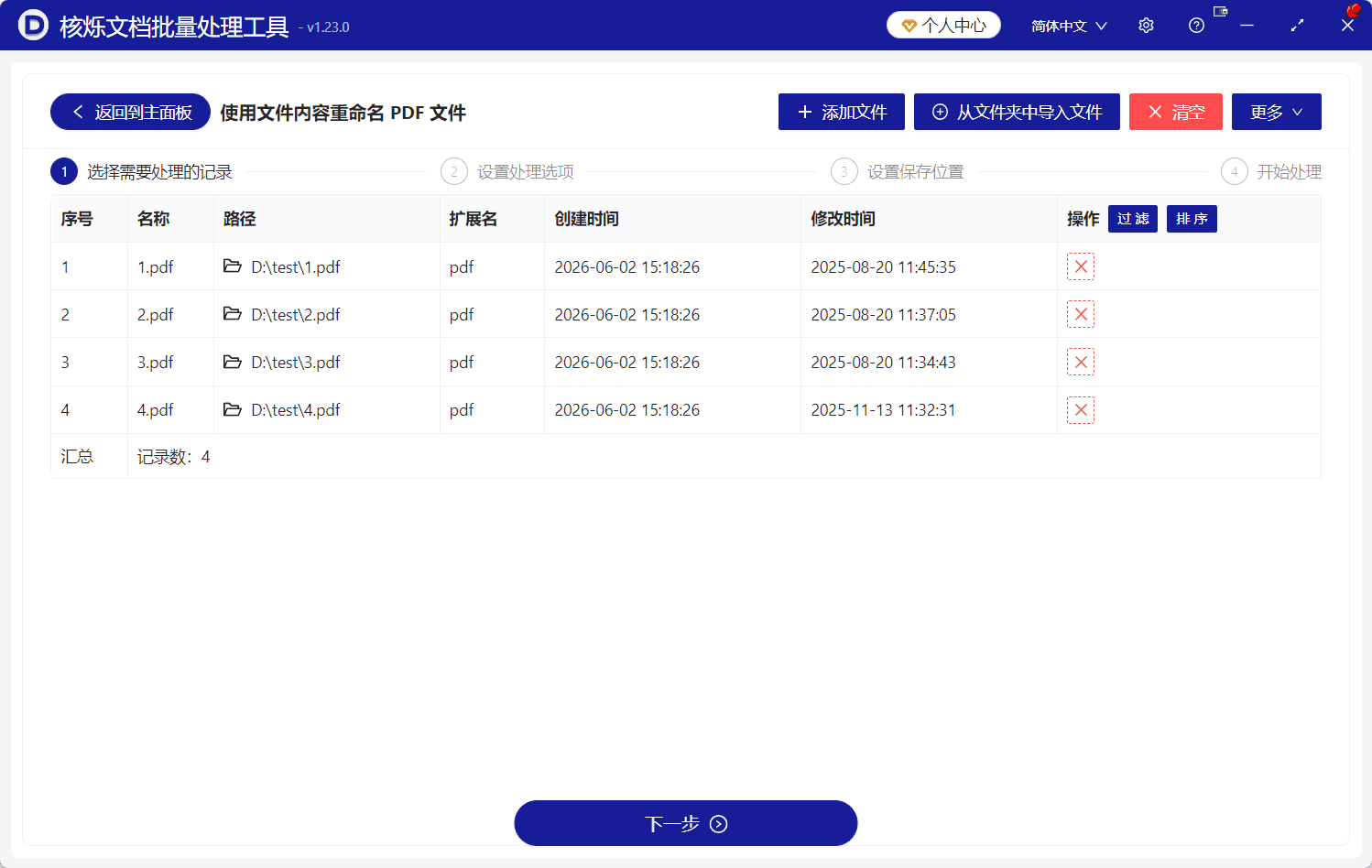
截图中已导入4个PDF,名称为1.pdf、2.pdf、3.pdf、4.pdf,路径显示在D盘test目录下。此时要确认列表中的文件就是你准备处理的文件。如果发现导入错误,可以通过右侧操作列删除,或使用“清空”重新选择。
确认记录无误后,点击底部“下一步”。这一步的预期结果是:所有待重命名的PDF都出现在列表中,并准备进入规则设置。
步骤三:选择“第一行文本”作为查找区域
进入第2步“设置处理选项”后,页面顶部显示“查找区域”。这里决定软件从PDF中提取什么内容来作为新文件名。截图中可选项包括“第一行文本”“第一个条形码图片”“自定义公式匹配到的文本”。
因为本文要使用PDF中的第一行文字重命名文件,所以选择“第一行文本”。截图中红框已经标出该选项。
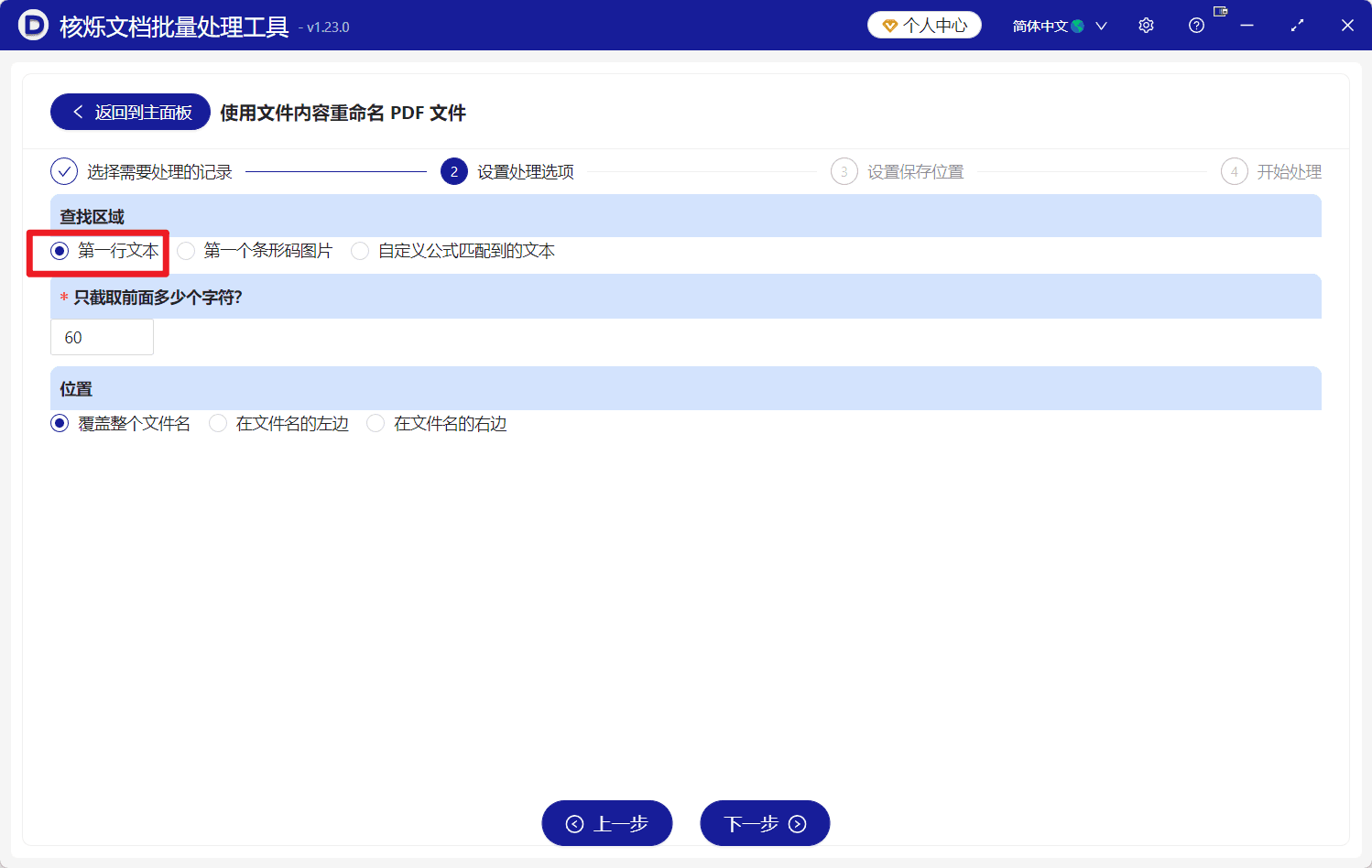
选择完成后,软件会按这一规则读取PDF文本。对于首页标题位于开头位置的PDF,这个设置通常可以快速得到符合预期的文件名。比如PDF内容第一行是“NASA Office of Inspector General”,处理后文件名也会相应变为这个标题。
步骤四:设置文件名截取长度,避免名称过长
在“查找区域”下方,有一个设置项:“只截取前面多少个字符?”。截图中的数值是60。它的含义是:从提取到的第一行文本中,最多取前60个字符作为文件名。
这项设置很重要。很多PDF标题比较长,如果完整写入文件名,可能导致文件名在资源管理器中显示不完整,也可能让目录显得混乱。设置合理的截取长度,可以在保留关键信息的同时,让文件名更简洁。
对于合同类文件,如果标题通常较短,可以设置为60;对于报告类文件,如果标题较长但前半部分已经能表达主题,也可以设置为40到60之间。实际使用时,建议先用少量PDF测试,检查文件名是否被过度截断。
步骤五:选择覆盖整个文件名
继续查看“位置”区域,可以看到三个选项:“覆盖整个文件名”“在文件名的左边”“在文件名的右边”。如果原文件名没有保留价值,例如1.pdf、2.pdf这种纯数字名称,应选择“覆盖整个文件名”。
覆盖整个文件名后,软件会用提取到的第一行文字替换原来的文件名,同时保留PDF文件扩展名。也就是说,1.pdf会变成类似“Learn English in an easy.pdf”的名称。
如果你的原文件名包含日期、编号或其他有用信息,也可以考虑把提取文本插入到左边或右边。但在大多数整理序号PDF的场景中,覆盖整个文件名更清楚,也更符合归档要求。
步骤六:设置保存位置并执行处理
完成处理选项后,点击“下一步”,进入第3步“设置保存位置”。该步骤用于确定处理后的PDF保存到哪里。对于重要文件,建议不要一开始就直接覆盖原目录,可以先输出到一个新的文件夹,检查结果无误后再归档。
保存位置设置完成后,继续进入第4步“开始处理”。软件会根据导入列表逐个读取PDF内容,提取第一行文本,并按照“覆盖整个文件名”的规则生成新名称。处理完成后,打开保存位置即可查看结果。
从处理后截图可以看到,文件名已经成功按PDF内容重命名。原本无法识别的序号文件,变成了具有标题信息的PDF文件。
常见问题或注意事项
1. PDF首页第一行不是标题怎么办?
如果首页第一行是页眉、编号、空白或其他无关内容,使用“第一行文本”可能得不到理想文件名。建议先查看PDF版式,确认第一行文字是否适合作为文件名。如果不适合,可考虑按文件类型分批处理,或使用软件界面中提供的其他匹配方式进行尝试。
2. 为什么处理后文件名只保留了一部分?
这通常与“只截取前面多少个字符?”有关。如果设置为60,而标题超过60个字符,后面的内容就不会进入文件名。可以根据需要调大数值,但也要避免文件名过长。
3. 处理大量PDF前应该怎么做?
建议先选取3到5个具有代表性的PDF测试。检查提取出来的文件名是否准确、长度是否合适、是否符合归档规范。确认无误后,再批量导入完整文件夹处理。
4. 文件名重复会怎样?
如果多个PDF的第一行文字完全相同,可能会出现文件名重复的情况。正式处理前应关注同类文件是否存在相同标题。对于容易重复的资料,可以考虑保留原编号,或分批处理后人工检查。
5. 这种方法是否只适用于PDF?
本文介绍的是“使用文件内容重命名 PDF 文件”功能,主要面向PDF。软件界面中也能看到与Word文件、文本文件等相关的文件内容重命名功能,但处理doc、docx、txt等文件时应选择对应功能,不要混用。
总结:用批量处理提升PDF归档效率
把PDF首页标题批量设置为文件名,是一种简单但非常有效的资料整理方法。它解决了数字命名、随机命名、系统导出命名不直观的问题,让文件名直接反映文件内容。
借助核烁文档批量处理工具,你可以通过清晰的步骤完成这一操作:进入文件名称模块,选择“使用文件内容重命名 PDF 文件”,导入PDF,设置查找区域为“第一行文本”,控制截取字符数,选择覆盖整个文件名,最后设置保存位置并开始处理。
对于经常整理合同、报告、课件、说明书和各类PDF资料的用户来说,这类批量处理能力能够明显减少重复劳动。建议在正式处理前先小范围测试,确认规则符合预期后,再批量处理整个文件夹,让PDF归档更规范、更高效。