很多团队会把资料、笔记、文章草稿或说明文档保存为txt格式,但在发布、预览或归档时又需要html网页文件。面对一整个文件夹的记事本文档,手动逐个转换效率很低。本文介绍如何借助核烁文档批量处理工具,在文本工具中选择文本转换为HTML网页,批量导入txt文件并统一输出html结果,帮助办公用户快速完成格式转换。
如果你经常处理文档资料,应该遇到过这样的情况:一个项目目录里存放着大量txt记事本文件,每个文件都是一篇说明、一段资料或一份记录。txt格式虽然简单,但它更适合纯文本编辑;一旦需要用浏览器打开、作为网页素材归档,或者交给网站、知识库、内容系统继续使用,就需要转换为html网页文件。单个txt转html并不难,真正麻烦的是“很多个txt要一起转”。
手动处理这类任务通常会浪费大量时间。比如打开第一个txt,复制内容,新建html,保存;再打开第二个txt,重复同样操作。文件越多,越容易出现漏转、重名、保存位置不一致等问题。对于办公软件来说,批量处理文件的价值正体现在这里:把重复性强、规则明确的操作集中完成,让用户只负责选择文件和确认结果。
下面以核烁文档批量处理工具为例,演示如何把多个记事本txt文件批量生成html网页。本文会按照处理前效果、软件操作、处理后结果和注意事项展开,适合正在搜索“txt批量转换HTML”“多个记事本转网页”“txt文件夹转html格式”的用户参考。
适用场景:为什么要把txt文件夹批量转换为html
txt文件夹批量转html适合很多实际办公场景。第一类是资料归档。例如技术部门、行政部门或培训团队保存了大量纯文本资料,希望后续通过浏览器快速预览,就可以将txt统一转换成html。第二类是内容发布。运营或编辑人员可能先用记事本保存文章草稿,等内容确认后再转成网页格式,交给网站或其他系统继续处理。第三类是文档迁移。旧系统导出的内容可能是txt,迁移到新系统前需要先生成html文件,方便后续导入、校对或二次加工。
另外,html文件相比txt更适合网页环境。许多电脑默认会用浏览器打开html,查看方式更接近最终页面效果。对于需要交付给同事、客户或技术人员的资料,html文件也更容易被识别为网页内容。批量转换后,每个txt都能生成一个同名html,便于保持对应关系。
需要注意的是,本文介绍的是“文本转换为HTML网页”,也就是从txt、记事本、纯文本文件生成html文件。它不同于“HTML转换为TXT”,后者是把网页文件转回纯文本。选择功能时一定要看清转换方向。
效果预览:从txt源文件到html网页文件的变化
处理前,文件夹中是一组txt记事本文档。从截图可以看到,文件名分别是big_bang.txt、black_holes.txt、dark_energy.txt、dark_matter.txt、galaxies.txt。这些文件的共同特点是扩展名为.txt,属于纯文本文件,通常通过记事本或文本编辑器打开。

经过批量转换后,输出目录中出现了对应的html文件。截图显示,文件名主体保持不变,只是扩展名变成了.html,例如big_bang.html、black_holes.html、dark_energy.html、dark_matter.html、galaxies.html。图标显示为浏览器相关样式,说明系统会将它们识别为网页文件。

这种“同名转换”的结果非常适合批量核对。用户可以根据文件名快速确认每个txt是否都有对应html结果,也方便后续按主题、项目或日期继续整理。对于几十个文件甚至更多文件来说,保持命名对应能显著降低检查成本。
操作步骤:批量将记事本文档转换为HTML网页
步骤一:打开软件并定位到文本工具分类
启动核烁文档批量处理工具后,界面左上角显示软件名称,整体是面向办公用户的批量文档处理工具。左侧导航栏将功能按文件类型和处理方向进行了分类,例如文件名称、文件整理、Word工具、Excel工具、PDF工具、文本工具等。由于本次处理对象是txt记事本文档,所以需要点击左侧的“文本工具”。
进入文本工具后,中间区域会显示多个与文本相关的功能卡片。截图中可以看到“文本转换为Word”“文本转换为PDF”“HTML转换为TXT”“HTML转换为Word”“Markdown转换为HTML”等功能。对于本次任务,应选择“文本转换为 HTML 网页”。卡片说明中明确写着“批量将记事本文本文件转换为HTML网页格式”,这与“批量把txt转html”的目标一致。
这一步的目的,是确保进入正确的批量转换模块。办公软件中的功能较多,如果选错方向,输出结果就会不符合预期。看到“文本转换为 HTML 网页”后点击进入,即可开始添加待处理文件。
步骤二:导入需要处理的txt文件
进入功能页面后,顶部显示当前模块为“文本转换为 HTML 网页”。界面上方提供“添加文件”“从文件夹中导入文件”“清空”“更多”等按钮。页面中部是待处理文件列表,流程条显示当前处于第1步“选择需要处理的记录”。
如果你只想转换几个指定文件,可以点击“添加文件”,从电脑中选择这些txt文档。如果你的txt都在同一个文件夹里,更高效的方式是点击“从文件夹中导入文件”,一次性导入该目录下需要处理的文件。对于“txt文件夹转html”这种批量需求,从文件夹导入通常更省事,也更不容易漏选。
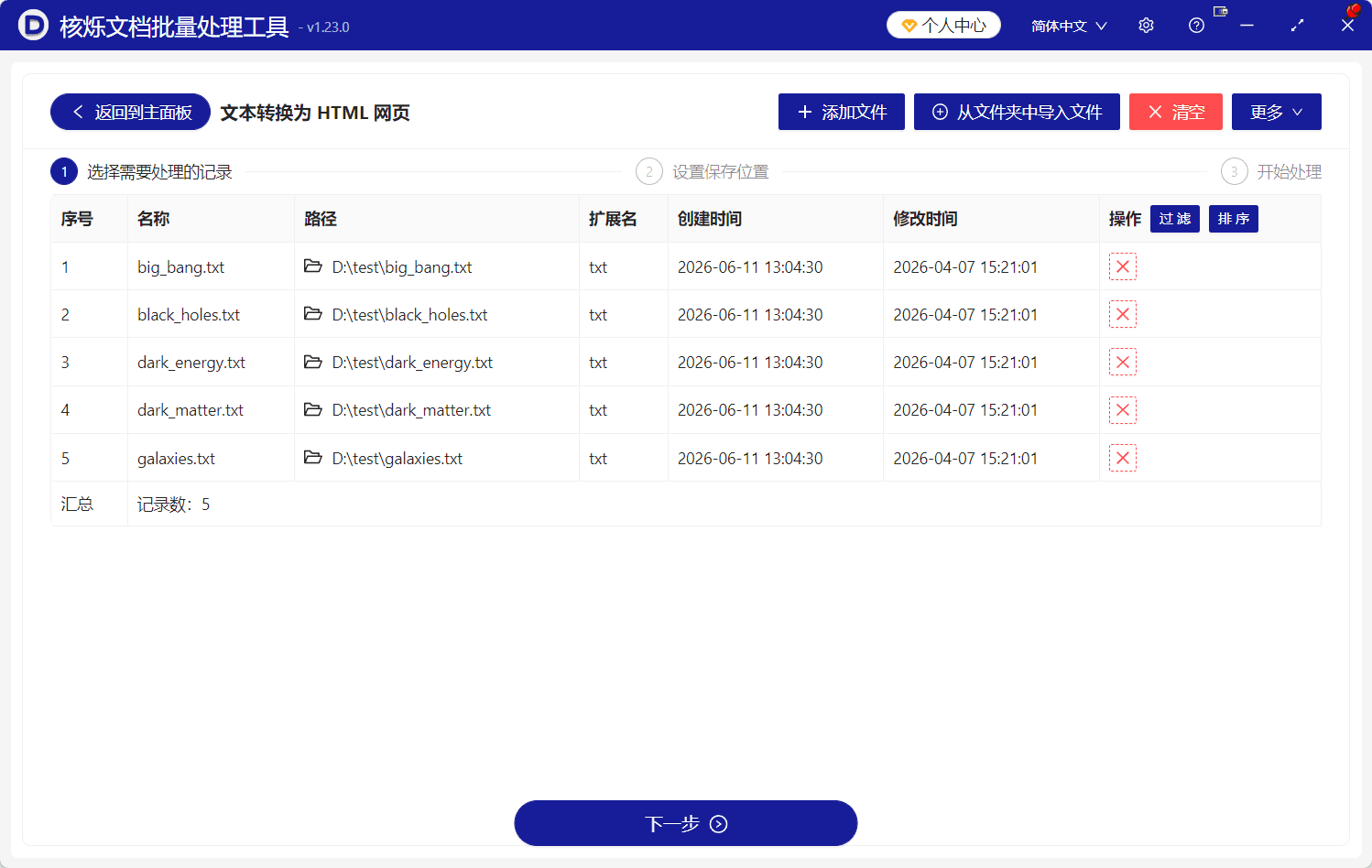
导入后,文件会出现在表格中。截图示例中共有5条记录,名称分别为big_bang.txt、black_holes.txt、dark_energy.txt、dark_matter.txt、galaxies.txt;路径列显示它们位于D:\test目录;扩展名列为txt;同时还显示创建时间和修改时间。底部“汇总”区域显示记录数为5,说明这5个文件已经进入待处理队列。
此时建议先检查一遍列表。重点看三项:第一,文件名称是否都是你要转换的txt;第二,路径是否来自正确文件夹;第三,扩展名是否为txt。如果发现文件选错,可以使用操作列中的删除图标移除;如果想重新选择,可以点击“清空”后重新导入。批量处理前的检查越仔细,后续返工越少。
步骤三:进入下一步并设置输出位置
确认文件列表无误后,点击底部的“下一步”。界面流程的第二项是“设置保存位置”,这表示软件会要求你指定html结果文件的保存目录。对于批量转换,保存位置的选择很关键。建议不要随意放在桌面或混在源文件目录中,而是建立一个专门的输出文件夹,例如“html_result”“网页文件”或项目名称加日期的目录。
把输出目录单独管理有两个好处:一是源txt文件和结果html文件不会混淆,便于备份和对比;二是处理完成后可以快速查看生成结果,不需要在大量源文件中查找。特别是当文件数量很多时,清晰的保存位置能节省大量核对时间。
这一步完成后,软件就具备了两个关键信息:要处理哪些txt文件,以及转换后的html文件保存到哪里。接下来就可以进入开始处理阶段。
步骤四:开始批量转换并检查输出结果
在流程的第3步“开始处理”中,按照界面提示启动任务。软件会根据导入列表逐个处理txt文件,并在指定位置生成html网页文件。与手动转换相比,这种方式的优势是流程统一、命名对应、减少人工重复点击。用户不需要逐个打开记事本,也不需要手动创建每一个html文件。
处理完成后,打开输出文件夹进行核对。你应该能看到与源文件一一对应的html结果,例如big_bang.html对应big_bang.txt,black_holes.html对应black_holes.txt。可以随机双击几个html文件,用浏览器打开检查内容是否符合预期。如果所有文件都已生成,说明这次批量txt转html任务完成。
常见问题与注意事项
1. 批量转换会不会改变原来的txt文件?
从转换结果来看,处理后会生成新的html文件,源文件名对应保留为txt。为了稳妥起见,处理重要资料时仍建议保留源文件备份,并将输出保存到独立目录。这样即使需要重新处理,也可以随时回到原始文本。
2. 文件很多时如何减少漏选?
如果所有txt都在同一目录,优先使用“从文件夹中导入文件”。导入后通过表格底部的记录数和文件列表进行确认。相比逐个选择文件,从文件夹导入更适合批量场景,尤其是几十个或上百个文件。
3. 可以同时处理不同名称的txt吗?
可以。从截图示例看,big_bang、black_holes、dark_energy等不同文件名都被加入同一个任务列表。批量处理的重点是扩展名和文件类型符合要求,文件名可以不同。为了后续网页文件管理,建议使用清晰、规范、容易识别的名称。
4. 输出为html后如何确认成功?
最直观的方法是查看输出目录中是否生成了对应的.html文件,并随机打开几个文件检查。截图中的处理后效果显示,文件图标变为浏览器样式,扩展名为html,这就是转换成功的重要标志之一。
5. 这种方法和Word、docx、PDF转换有什么区别?
本文针对的是txt纯文本到html网页格式的转换。如果你的源文件是Word文档,例如doc或docx,或者是PDF文件,就需要选择对应的Word工具或PDF工具功能。不同文件类型应进入相应模块,避免把txt转换流程误用于其他格式。
总结:用批量处理方式完成txt到html的格式迁移
多个记事本文件批量生成HTML,本质上是一项典型的办公自动化任务:规则明确、文件数量多、人工操作重复。使用核烁文档批量处理工具,可以通过“文本工具”中的“文本转换为 HTML 网页”功能,将一批txt文件统一导入,检查列表后设置保存位置,再集中生成html网页文件。
相比手动逐个转换,批量处理能明显减少时间消耗,也能降低漏选、错存、命名混乱等风险。对于内容整理、网页素材准备、资料归档和文本格式迁移等场景,这种方法更稳定、更适合规模化处理。如果你手头正有一整个文件夹的txt需要转成html,建议按照本文流程先导入少量文件测试,确认结果后再批量处理全部资料,这样既高效又稳妥。