当大量 TXT 文本文件仍以 book1.txt、book2.txt 这类临时名称保存时,手动逐个打开、复制编号再重命名非常耗时。本文介绍如何使用核烁文档批量处理工具,根据文本文件内容中的指定文字批量重命名 TXT 文件,例如提取每个文件第一行 Book ID 后面的数字,并将其作为新的文件名。通过添加文件、设置正则表达式匹配规则、选择覆盖文件名并执行处理,即可一次完成多个文本文件改名,适合资料归档、电子书整理、日志文件编号管理等场景。
在整理 TXT 文本文件时,经常会遇到这样的情况:文件夹里有一批名称没有实际意义的文件,例如 book1.txt、book2.txt、book3.txt,但每个文件内部都包含真正可用于归档的编号、标题或名称。如果逐个打开文件、复制内容、再回到文件夹里重命名,不仅步骤重复,而且很容易复制错、漏改或改乱。
本文要解决的问题就是:批量使用文件中的部分文字来重命名 TXT 文件。下面以核烁文档批量处理工具为例,演示如何提取文本内容中 Book ID 后面的数字,并将这些数字批量设置为 TXT 文件名。
适用场景
使用文件内容批量重命名文本文件,适合以下场景:
- 电子书、文章、资料文件内部有唯一编号,希望用编号作为文件名。
- 日志、订单、合同摘要等 TXT 文件中包含 ID、流水号、日期等字段,需要按字段归档。
- 下载或导出的文本文件名称是 book1.txt、book2.txt 这类临时名称,需要批量规范化。
- 文件内容中有固定格式,例如 Book ID:4829173056,希望只提取其中的数字部分作为文件名。
核烁文档批量处理工具是一款面向办公场景的批量文件处理软件,核心价值是减少重复操作。对于 TXT、文本资料等文件整理任务,它可以让用户通过规则一次处理多份文件,避免反复打开、复制、粘贴和重命名。
效果预览:处理前和处理后
处理前:文件名没有实际业务含义
处理前,文件夹中的 TXT 文件名称类似:
- book1.txt
- book2.txt
- book3.txt
- book4.txt
- book5.txt
这些名称只能表示顺序,无法直接看出文件对应的编号或内容。打开其中一个文本文件后,可以看到文件内容第一行包含类似 Book ID:4829173056 的信息。这里真正需要用于命名的是冒号后面的数字 4829173056。


处理后:提取文件内容中的编号作为文件名
批量处理完成后,文件名会变成类似:
- 1958436720.txt
- 4829173056.txt
- 6094728315.txt
- 7305619482.txt
- 8640295173.txt
可以看到,每个 TXT 文件都不再使用 book1、book2 这类临时名称,而是使用文件内容中提取到的编号进行命名。文件扩展名仍然保持为 .txt,便于继续作为文本文件打开和管理。
操作步骤
步骤一:进入“使用文件内容重命名文本文件”功能
打开核烁文档批量处理工具,在左侧功能分类中选择 文件名称。在功能列表中找到并点击 使用文件内容重命名文本文件。
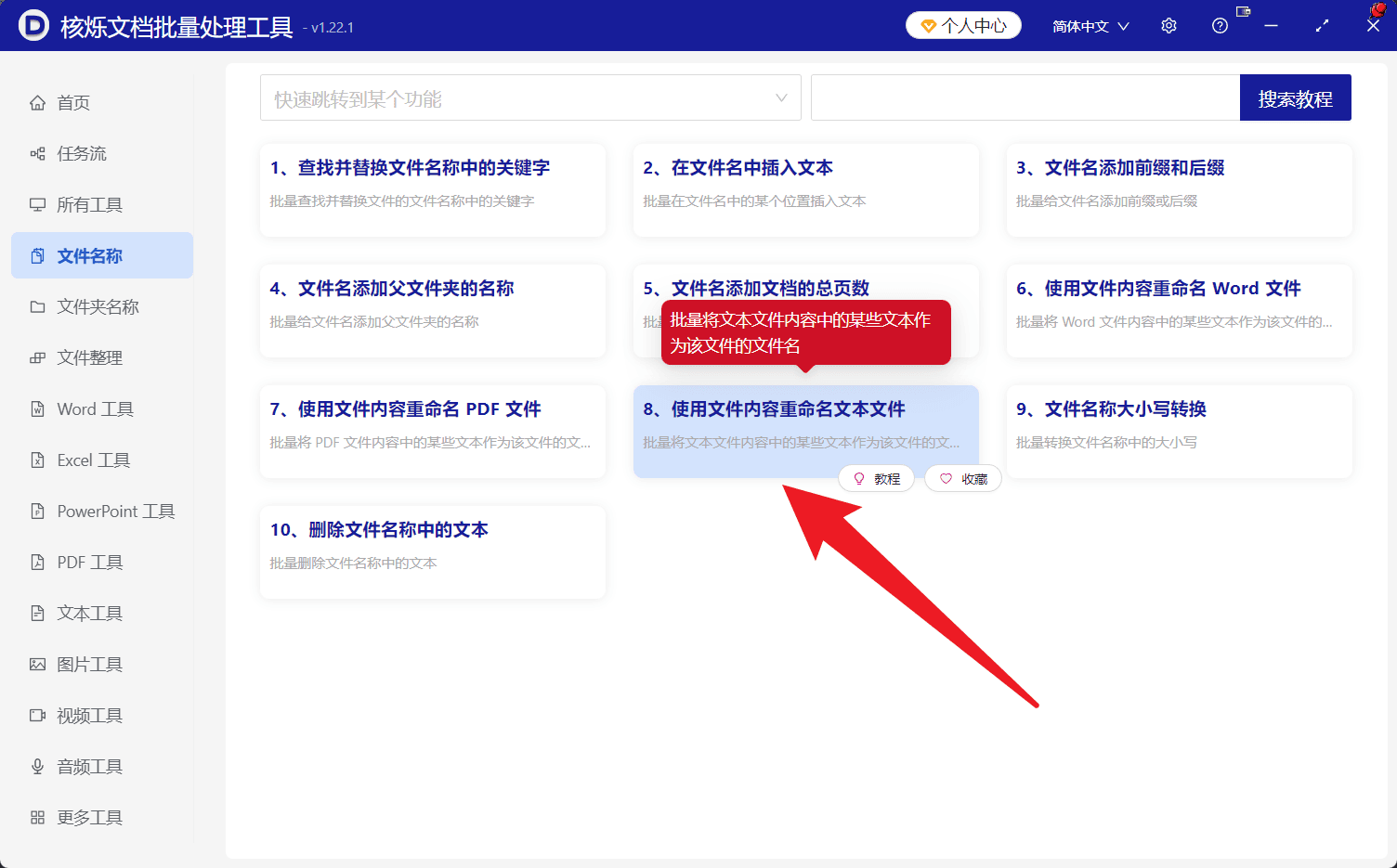
这个功能的用途是:批量读取文本文件内容,并将内容中的某些文本作为文件名。截图中该功能说明为“批量将文本文件内容中的某些文本作为该文件的文件名”,与本文要实现的批量使用 TXT 内容重命名文件完全对应。
进入该功能后,界面会进入分步骤向导,包括“选择需要处理的记录”“设置处理选项”“设置保存位置”“开始处理”等流程,按顺序完成即可。
步骤二:添加需要批量重命名的 TXT 文件
在第 1 步“选择需要处理的记录”页面,点击顶部的 添加文件 按钮,将需要处理的 TXT 文件加入列表。如果文件集中保存在同一个文件夹中,也可以使用 从文件夹中导入文件。
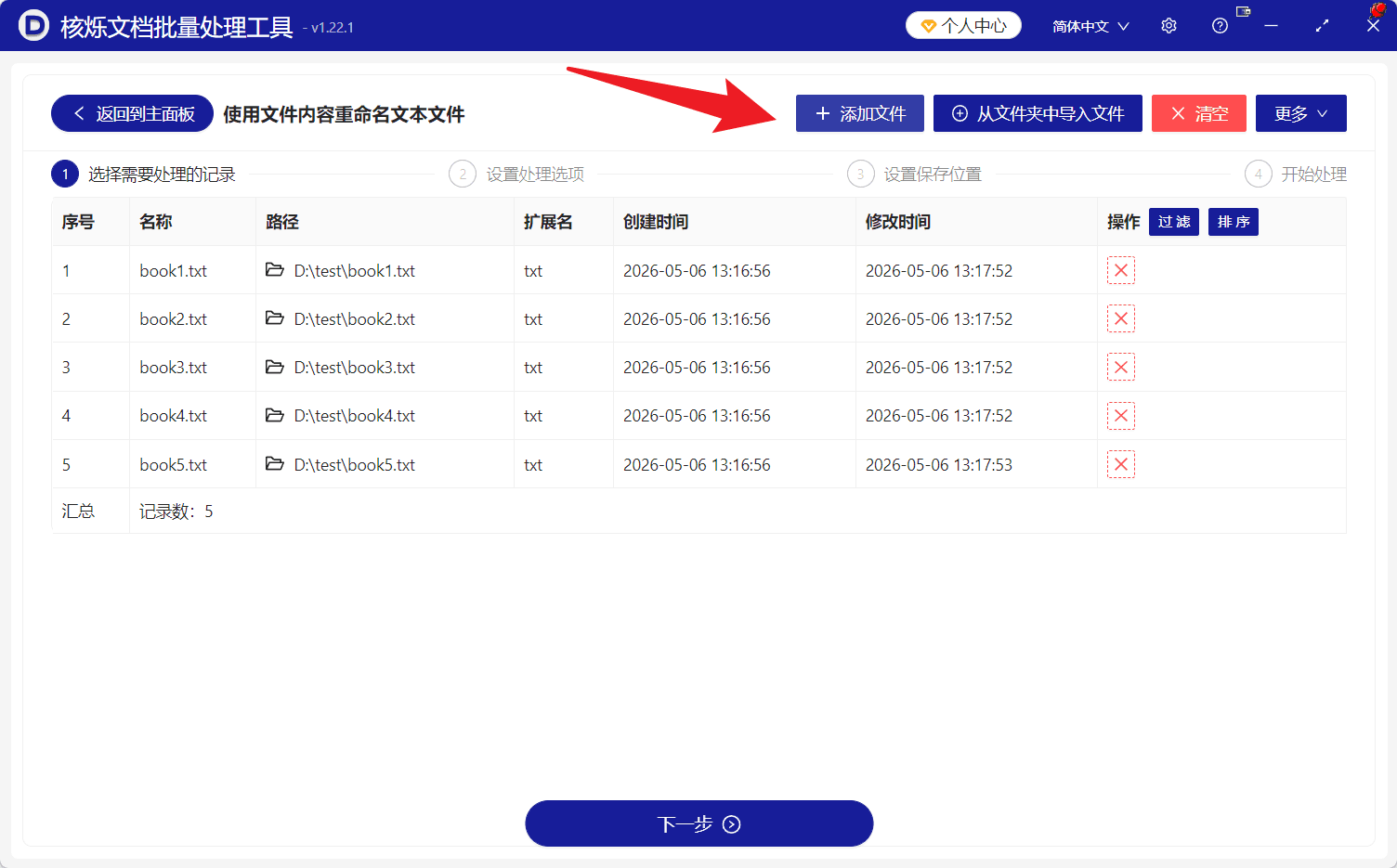
文件添加后,列表中会显示序号、名称、路径、扩展名、创建时间、修改时间等信息。例如截图中已导入 book1.txt 到 book5.txt 共 5 个文本文件,扩展名均为 txt。
这一步的目的,是让软件明确接下来要处理哪些文件。添加完成后,检查列表中的文件是否正确,确认无误后点击底部的 下一步。
步骤三:设置从文件内容中提取哪一部分文字
进入第 2 步“设置处理选项”后,需要告诉软件从 TXT 文件内容的哪个区域、按什么规则提取文字。
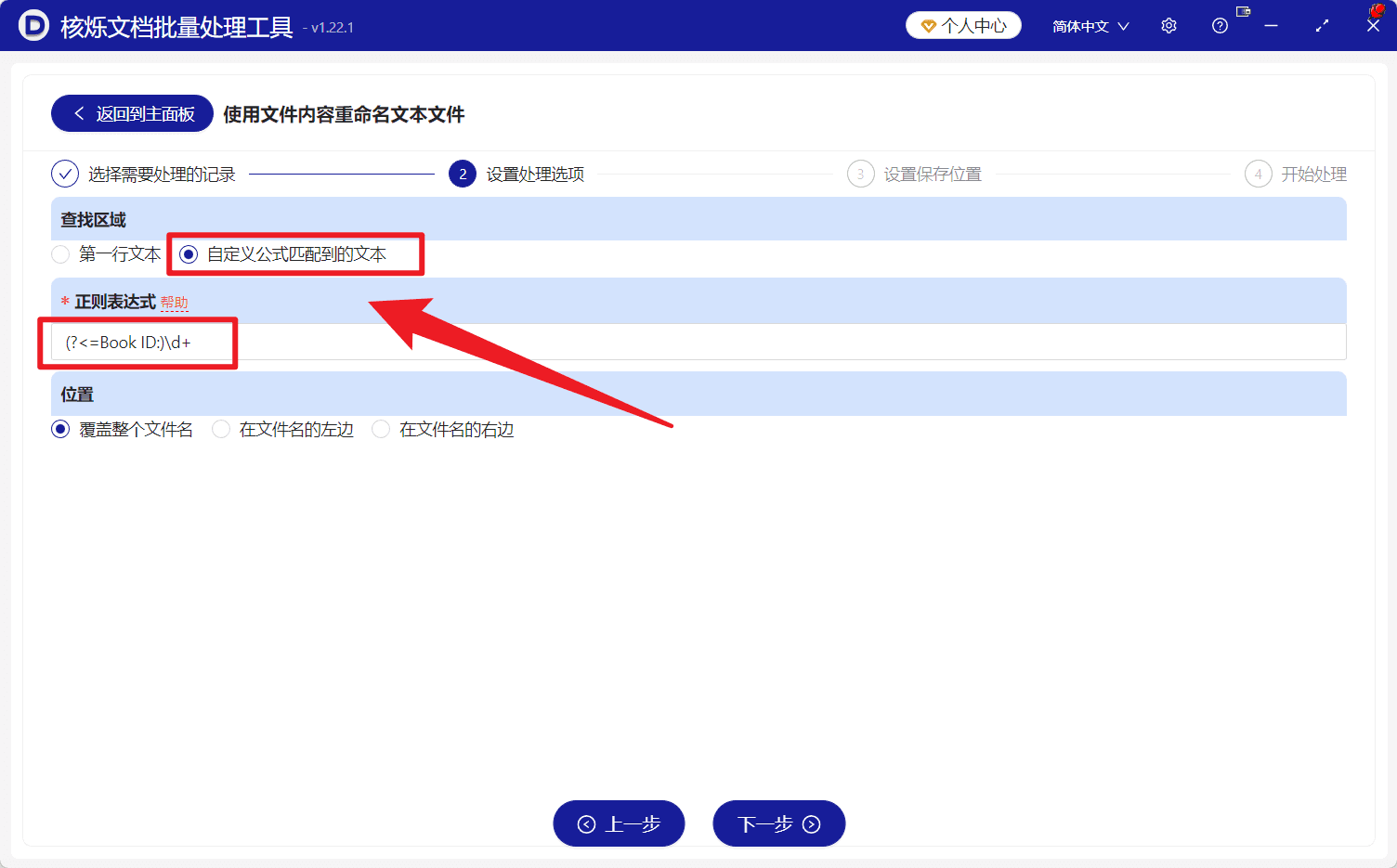
在“查找区域”中,可以看到有 第一行文本 和 自定义公式匹配到的文本 等选项。本文示例中,虽然目标内容出现在第一行,但我们只需要提取 Book ID: 后面的数字,而不是整行文字,因此选择 自定义公式匹配到的文本。
然后在“正则表达式”输入框中填写:
(?<=Book ID:)\d+
这个表达式的含义是:查找紧跟在 Book ID: 后面的连续数字。以内容 Book ID:4829173056 为例,最终匹配到的结果就是 4829173056。
如果你的文件内容格式不同,可以根据实际文本调整匹配规则。例如前缀不是 Book ID,而是 Order ID、编号、ID 等,就需要对应修改正则表达式中的固定文字。
步骤四:设置文字放入文件名的位置
在同一页面的“位置”区域,可以选择提取到的文字如何应用到文件名中。截图中提供了以下选项:
- 覆盖整个文件名
- 在文件名的左边
- 在文件名的右边
本文的目标是将原来的 book1、book2 等名称替换为文件内容中的编号,因此选择 覆盖整个文件名。
选择该选项后,软件会用匹配到的数字替换原文件名主体,并保留文本文件扩展名。例如 book1.txt 中匹配到 4829173056,处理后会变为 4829173056.txt。
如果你只是想在原文件名前面或后面追加内容,可以改选“在文件名的左边”或“在文件名的右边”。但对于本示例的“用内容编号作为新文件名”需求,应选择覆盖整个文件名。
步骤五:继续设置保存位置并开始处理
完成提取规则和命名位置设置后,点击 下一步,进入“设置保存位置”。根据界面向导完成保存位置设置后,再进入“开始处理”。
由于这是批量重命名操作,建议在正式处理前先确认三点:
- 文件列表中的 TXT 文件是否都是本次需要处理的文件。
- 正则表达式是否能准确匹配到目标内容。
- 命名方式是否选择为“覆盖整个文件名”。
确认无误后执行处理。处理完成后,回到文件夹即可看到 TXT 文件已经批量改名为内容中的编号。
正则表达式说明:为什么使用 (?<=Book ID:)\d+
在本例中,文本文件第一行类似:
Book ID:4829173056
我们只想要数字部分,不想把 Book ID: 一起放入文件名,所以使用了:
(?<=Book ID:)\d+
- (?<=Book ID:):表示匹配位置前面必须是 Book ID:,但不把 Book ID: 本身作为结果。
- \d+:表示匹配一个或多个数字。
因此,软件最终提取到的文件名文本就是数字编号。这个方法适合内容格式比较固定的 TXT 文件,特别是每个文件都包含同样字段名、但字段值不同的情况。
常见问题和注意事项
1. 如果文件里没有 Book ID 会怎样?
如果某个 TXT 文件中没有符合规则的内容,软件就无法按该规则提取到新文件名。处理前建议抽查几份文件,确认它们都有类似 Book ID:数字 的结构。
2. 正则表达式需要完全照抄吗?
不一定。本文示例适用于 Book ID:4829173056 这种格式。如果你的内容是“编号:4829173056”或“ID=4829173056”,就需要根据实际前缀修改表达式。
3. 提取到的文本可以包含中文或标题吗?
该功能的思路是从文本文件内容中提取指定文字作为文件名。只要能通过查找区域或匹配规则定位到目标文字,就可以用于重命名。实际使用时要注意文件名中不要包含系统不允许的特殊字符。
4. 会不会改变 TXT 文件内容?
本文演示的是文件名称处理,目标是批量修改文件名。处理前后,关注的是文件名从 book1.txt 变为编号.txt,文件扩展名仍为 txt。
5. 批量处理前需要备份吗?
对于重要资料,建议先复制一份测试文件夹,再进行批量重命名。确认规则正确后,再处理正式文件。这样可以避免因规则设置不准确导致文件名不符合预期。
总结
批量使用文件中的部分文字来重命名 TXT 文件,本质上是把“打开文件、找到编号、复制编号、返回文件夹、修改文件名”这一串重复动作交给办公软件自动完成。通过核烁文档批量处理工具的“使用文件内容重命名文本文件”功能,只需要添加文件、设置匹配规则、选择覆盖文件名并执行处理,就能一次性完成多份文本文件的规范命名。
如果你正在整理大量 TXT、日志、资料、电子书文本文件,并且文件内容中已经包含编号、标题或其他可识别字段,建议使用这种批量重命名方法。它能明显减少重复劳动,提高文件归档效率,也能让后续查找和管理更加清晰。