面对大量本地html、mhtml网页文件,如果逐个用浏览器打开再保存为PDF,过程繁琐且容易出错。本文围绕多个网页文件一键转PDF的办公需求,介绍如何在核烁文档批量处理工具中找到“HTML转换为PDF”,导入文件或文件夹,核对任务列表,设置保存位置并完成批量转换,帮助用户快速得到可归档、可打印、可分享的PDF文件。
很多办公人员都会遇到类似情况:电脑文件夹里保存了一批网页文件,有些是html格式,有些是mhtml格式,它们可能来自系统导出、浏览器保存、网页采集、历史资料备份或客户提供的离线页面。现在需要把这些网页文件统一整理成PDF,用于汇报、归档、打印、提交或分享。若文件只有一两个,手动打开浏览器再保存为PDF还能接受;但当文件数量较多时,这种方法会变得低效,而且每个文件都要重复选择保存路径和文件名,稍不注意就会漏掉或覆盖。
这篇文章将说明如何借助核烁文档批量处理工具,把多个html网页文件一次性转换为PDF。该软件属于办公文件批量处理工具,核心价值在于把重复、机械、容易出错的文件处理动作集中完成。通过“HTML转换为PDF”功能,可以把网页格式资料转为更常用的PDF文档,让后续查看、传输和归档更方便。
适用场景:本地网页文件批量转PDF的典型需求
多个网页文件转PDF常见于资料管理和文档交付场景。比如,企业后台导出的订单页面、统计页面、审批记录页面,通常会以网页形式保存;研发或测试人员保存的接口说明、测试报告、页面快照,也可能是html文件;内容运营、法务、行政人员在做网页留存时,可能会把网页保存成mhtml文件。这些文件如果长期以网页格式存在,后续打开时会受到浏览器环境、资源路径和文件结构影响。
PDF则更接近标准办公文档。它适合发给同事、客户或外部单位,也适合集中放入档案目录。对于需要打印的资料,PDF也比网页文件更容易控制阅读和输出效果。因此,当你手上有一批html、mhtml文件,并希望它们变成可归档、可共享的文档时,批量转换PDF就是更高效的处理方式。
尤其是在文件数量较多的情况下,批量处理工具的优势会非常明显。它不要求用户重复执行“打开网页—打印—选择PDF—保存—关闭页面”的流程,而是把文件加入任务列表后统一处理。这正是办公软件提升效率的关键:把人的时间从重复点击中解放出来,减少人为失误。
效果预览:转换前的网页文件状态
在转换前,文件夹中有多个网页文件。如下图所示,文件包括1.mhtml、2.html、3.html、4.html,图标显示为浏览器相关图标。它们可以被浏览器打开,但作为办公交付文件并不够统一。

从文件名可以看出,这些网页文件已经按序号命名。对于批量处理来说,清晰的命名很重要,因为转换后通常会生成对应名称的PDF文件。建议在正式转换前先整理源文件,例如删除不需要的文件、统一命名规则、把同一批资料放入同一个文件夹。这样后续导入和核对会更顺畅。
效果预览:转换后的PDF文件结果
转换完成后,原先的网页文件被生成对应的PDF文档,如1.pdf、2.pdf、3.pdf、4.pdf。PDF图标清晰,文件格式统一,适合继续归档、发送或打印。

这种结果对于办公整理非常友好:原文件名和新文件名之间具有对应关系,用户可以快速判断哪个PDF来自哪个网页文件。如果后续需要把这些PDF上传到系统、发送给同事,或按项目目录保存,也不需要再逐个重命名。
操作步骤:在核烁文档批量处理工具中完成HTML批量转PDF
下面按照软件界面截图,说明完整操作思路。由于不同用户的文件数量和目录结构不同,实际操作时可以根据自己的资料位置选择添加文件或从文件夹导入。
步骤一:打开软件并进入文本工具分类
启动核烁文档批量处理工具后,可以看到左侧有多个功能分类,包括文件名称、文件夹名称、文件整理、Word工具、Excel工具、PowerPoint工具、PDF工具、文本工具、图片工具等。由于HTML网页文件属于文本/网页类文件处理需求,因此这里选择左侧的“文本工具”。
进入文本工具后,主区域会显示多个相关功能卡片,例如文本转Word、文本转PDF、HTML转换为TXT、HTML转换为Word、HTML转换为PDF、Markdown转换为PDF等。用户需要根据目标格式选择正确入口。本次目标是把网页文件转成PDF,所以应选择“HTML转换为PDF”。
截图中“HTML转换为PDF”功能卡片被明显标出,说明该功能用于批量将HTML文件转换为PDF文档格式。这一步的预期结果是进入正确的转换模块,避免把文件误转成TXT、Word或其他格式。
步骤二:进入HTML转换为PDF页面,准备导入文件
点击“HTML转换为PDF”后,软件进入该功能的任务页面。页面左上方显示“返回到主面板”和当前功能名称“HTML转换为PDF”,说明用户已经进入批量转换流程。界面顶部流程条显示三个阶段:选择需要处理的记录、设置保存位置、开始处理。
这种分步式界面适合批量文件处理。第一步先把源文件整理进任务列表,第二步指定输出位置,第三步再执行转换。相比直接开始处理,这种流程能让用户在转换前有机会核对文件范围,减少误操作。
步骤三:通过添加文件或文件夹导入网页文件
在任务页面上方,可以看到“添加文件”“从文件夹中导入文件”“清空”“更多”等按钮。如果你的网页文件分散在不同位置,可以使用“添加文件”逐批选择;如果所有html、mhtml文件已经放在同一个文件夹里,更建议使用“从文件夹中导入文件”,一次性导入会更省时。
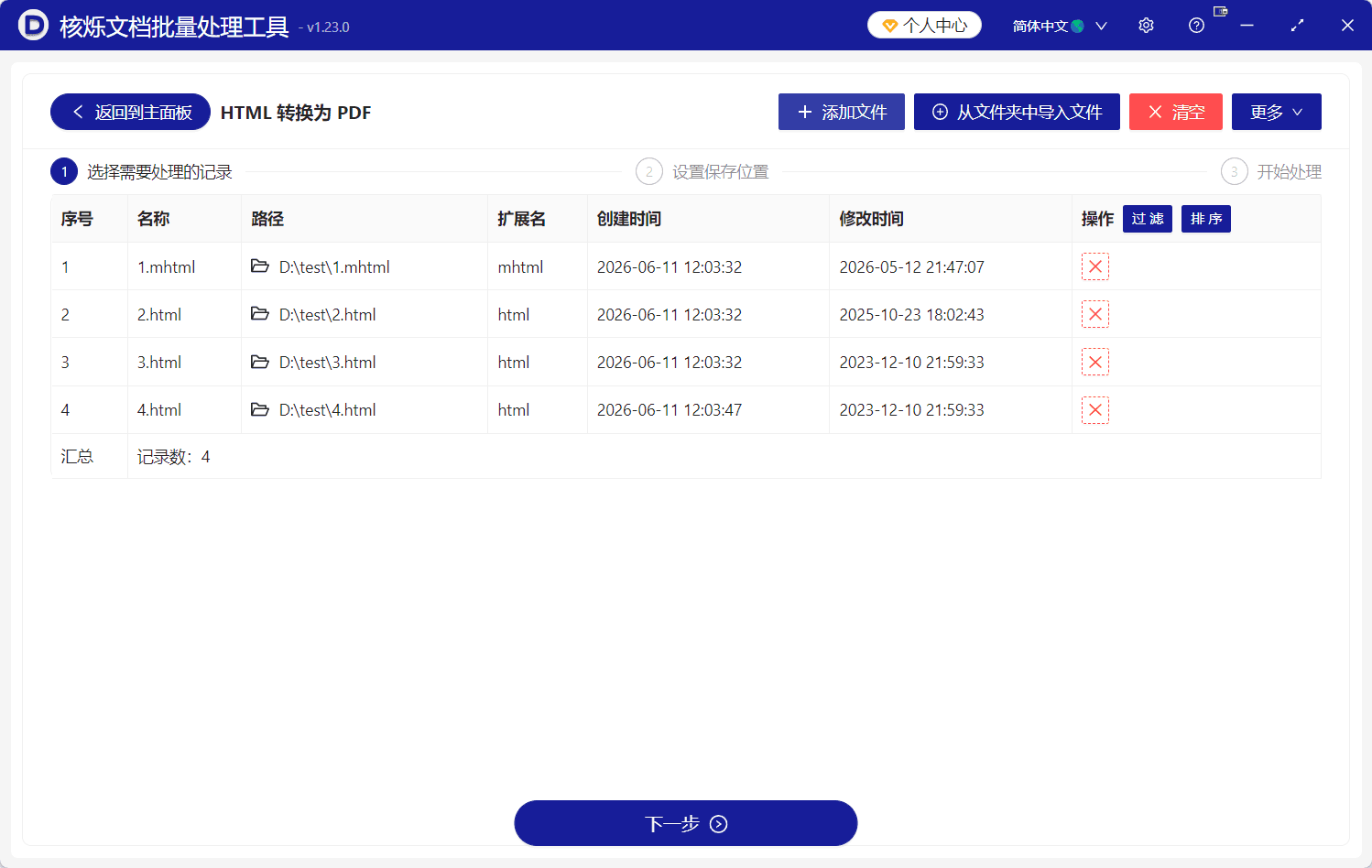
截图中,列表已经成功导入4个文件。表格字段包括序号、名称、路径、扩展名、创建时间、修改时间和操作。文件扩展名中既有mhtml,也有html,说明任务列表能够展示不同网页文件类型。底部汇总位置显示记录数为4,用户可以据此确认本次将处理4个文件。
这一步的操作目的,是把所有需要转换的网页文件一次性加入批量任务。预期结果是:待转换文件全部出现在表格中,并且名称、路径和扩展名信息正确。如果发现列表为空,说明还没有成功导入;如果记录数少于预期,可能需要重新检查文件夹或补充添加文件。
步骤四:核对文件列表,删除不需要处理的记录
批量处理的效率很高,但也意味着一旦任务范围选错,可能会批量生成不需要的结果。因此在点击下一步之前,建议认真核对列表。可以重点看三个信息:文件名称是否属于本批资料,路径是否来自正确文件夹,扩展名是否为需要转换的网页格式。
截图中每一行右侧都有操作区域,并显示删除样式的按钮。如果不小心加入了无关文件,可以通过该操作移除单条记录。界面右上方还有“清空”按钮,适合在导入错误较多时清空列表后重新选择。对于记录较多的场景,表头附近的过滤、排序按钮也有助于查看列表。
这一步的预期结果,是得到一个准确、干净的待处理列表。只有确认所有文件都需要转换后,再进入下一阶段,才能避免后续返工。
步骤五:点击下一步并设置PDF输出位置
列表核对完成后,点击页面底部的“下一步”按钮。根据流程提示,下一阶段是“设置保存位置”。对于批量转换PDF来说,输出位置非常重要。建议不要直接把结果散落在多个目录中,而是选择一个专门的文件夹,例如“网页PDF结果”“项目网页归档PDF”或按日期命名的输出目录。
合理的保存位置可以带来两个好处:一是方便转换后快速检查结果,二是避免PDF文件与原始html文件混在一起导致管理混乱。如果你需要保留源文件,最好将源文件夹和PDF结果文件夹分开保存;如果要提交给他人,则可以在转换完成后直接打包输出目录。
截图没有展示保存位置页面的具体按钮名称,因此这里不展开不存在于截图中的细节。实际操作时,按照软件进入第二步后的提示完成保存位置设置即可。
步骤六:开始处理,等待网页文件生成PDF
保存位置设置完成后,进入“开始处理”阶段。软件会按照任务列表中的文件顺序进行转换,把多个网页文件批量生成PDF。处理时间取决于文件数量、网页内容复杂程度以及电脑性能。一般来说,批量转换能够显著减少人工干预,用户不必逐个打开浏览器保存。
处理完成后,打开输出目录进行检查。如果结果与示例一致,应能看到与源文件对应的PDF文件。例如1.mhtml生成1.pdf,2.html生成2.pdf,3.html生成3.pdf,4.html生成4.pdf。建议至少抽查几个PDF,确认内容完整、页面可以正常阅读。如果这些文件要用于正式归档或对外发送,最好逐份快速浏览标题页或关键内容。
常见问题或注意事项
1. 转换前是否需要安装浏览器?
截图显示源文件图标与浏览器相关,但本文只根据软件界面说明操作流程。实际转换是否依赖浏览器环境,应以软件运行要求为准。对于用户来说,更重要的是确保html或mhtml源文件本身可以正常打开,避免源文件损坏影响转换结果。
2. 为什么有些网页转成PDF后样式可能不同?
html文件可能依赖外部图片、CSS样式或脚本资源。如果这些资源没有和html文件一起保存,打开网页时就可能显示不完整,转换成PDF后也会受到影响。mhtml通常会封装更多网页资源,但也建议在转换前抽查源文件是否能正常阅读。
3. 批量导入后记录数不对怎么办?
如果列表底部显示的记录数少于预期,可以检查文件是否放在正确目录,或者尝试使用“添加文件”补充导入。若导入了不需要的文件,可以删除单条记录或清空后重新导入。批量处理前的核对,比处理后再返工更省时间。
4. PDF是否会覆盖原来的HTML文件?
从效果图来看,转换后生成的是pdf文件,原始文件与输出文件扩展名不同。为了稳妥起见,建议设置单独的保存位置,这样既能保留源文件,也能让转换结果更清晰。
5. 文件很多时有什么建议?
如果一次要转换大量网页文件,可以先用少量样本测试转换效果,确认PDF内容符合要求后再处理全部文件。还可以按项目、日期或资料类别分批处理,这样更容易检查结果,也方便后续归档。
总结:把重复的网页转PDF工作交给批量处理工具
多个html、mhtml网页文件转换PDF,看似只是格式转换,实际涉及文件选择、命名、保存路径、结果核对等一系列重复操作。手动逐个处理不仅慢,而且容易出现漏转、错存、命名不一致等问题。使用核烁文档批量处理工具的“HTML转换为PDF”功能,可以把这些重复步骤整合成一个清晰流程:选择功能、导入文件、核对列表、设置保存位置、开始处理、检查结果。
对于经常整理网页资料、系统导出页面或项目归档文件的用户来说,建立批量转换流程能显著提升办公效率。下次遇到一整个文件夹的网页文件需要转PDF时,不必再逐个打开浏览器操作,直接使用批量处理工具完成即可。这样既节省时间,也能让输出文件更加规范、统一、便于管理。