当本地保存了大量html、mhtml网页文件时,逐个用浏览器打开再另存为PDF非常低效。本文围绕网页文件批量转PDF的办公需求,演示如何在核烁文档批量处理工具中找到“HTML 转换为 PDF”功能,批量导入网页文件,核对任务列表,设置保存位置并生成PDF。适合网页资料归档、业务报表留存、离线页面整理和统一文档格式转换等场景。
很多人在整理网页资料时都会遇到一个问题:文件夹里保存了大量 html 或 mhtml 文件,但最终需要提交、归档或发送给他人的格式却是 PDF。网页文件依赖浏览器打开,传输后也可能因为资源路径、默认打开方式不同而影响查看体验;PDF 则更适合办公流转,版式相对稳定,也便于打印、上传和长期保存。
如果只是一个网页文件,手动转换并不麻烦。但当文件数量很多时,逐个打开浏览器、选择打印、保存为 PDF、再确认文件名,会消耗大量时间。本文将介绍一种更适合办公场景的方法:使用“核烁文档批量处理工具”的“HTML 转换为 PDF”功能,把多个网页文件一次性加入处理列表,批量生成 PDF,减少重复操作。
适用场景:网页文件为什么要统一转换成PDF
网页文件转 PDF 不是单纯的格式变化,它通常对应着更明确的办公需求。比如企业内部系统导出的页面,有时是 html 或 mhtml;项目成员保存的网页资料,也可能以网页文件形式存放在本地。如果后续要给领导审批、给客户发送、放入项目档案或上传到平台,PDF 往往更符合要求。
常见应用包括:批量归档网页报告、整理本地保存的产品页面、转换培训课程网页、保存订单或业务记录页面、将离线网页资料做成统一的 PDF 文档包等。与 Word、docx、xlsx 这类办公文档类似,HTML 文件在整理阶段也经常需要转换成更通用的格式,而 PDF 正是最常见的输出格式之一。
对于文件数量较多的情况,批量处理办公软件的价值会更明显。它不是让用户重复执行单个文件操作,而是把一批文件放入同一个任务,统一转换、统一输出、统一核对。
效果预览:转换前后的文件变化
下面先看处理前的文件状态。示例文件夹中有 1.mhtml、2.html、3.html、4.html 等多个网页文件,图标显示为浏览器关联的文件类型。这说明它们通常需要通过浏览器打开查看,作为独立办公资料流转时不够统一。

批量转换完成后,网页文件生成了对应的 PDF 文件。示例中可以看到 1.pdf、2.pdf、3.pdf、4.pdf,文件数量与源文件对应,命名也便于核对。这样一来,原本分散的网页格式资料就变成了更便于归档和发送的 PDF 文档。

操作步骤:批量将HTML网页文件转换为PDF
以下步骤基于截图中的软件界面进行说明。核烁文档批量处理工具是一款面向办公文件批量处理的软件,界面中按文件类型和处理目的划分了多个工具分类。本次要完成的是 HTML 网页文件转 PDF,因此需要进入对应的文本工具功能。
第一步:在“文本工具”中找到“HTML 转换为 PDF”
打开软件后,左侧导航栏包含“首页”“任务流”“所有工具”“文件名称”“文件夹名称”“文件整理”“Word 工具”“Excel 工具”“PowerPoint 工具”“PDF 工具”“文本工具”等分类。由于本次处理对象是 HTML 网页文件,需要点击左侧的“文本工具”。
进入文本工具后,可以看到多个与文本、网页、Markdown 相关的转换功能,例如文本转换为 Word、文本转换为 PDF、HTML 转换为 TXT、HTML 转换为 Word、HTML 转换为 PDF、HTML 转换为 Markdown 等。这里应选择“HTML 转换为 PDF”。截图中该功能卡片被高亮,并显示说明“批量将 HTML 文件转换为 PDF 文档格式”。
这一步的关键是选对功能入口。因为 HTML 可以转换为多种格式,如果目标是生成 PDF,就不要选择 HTML 转换为 Word 或 HTML 转换为 TXT。正确进入“HTML 转换为 PDF”后,软件会打开对应的批量任务页面。
第二步:导入需要处理的网页文件
进入功能页面后,顶部可以看到“添加文件”“从文件夹中导入文件”“清空”“更多”等操作按钮。若文件数量较少,可以使用“添加文件”;若多个 html、mhtml 文件集中在一个目录中,更建议选择“从文件夹中导入文件”,这样更符合批量处理的目的。
导入后,文件会出现在列表中。截图中列表字段包括序号、名称、路径、扩展名、创建时间、修改时间和操作。示例已经导入 4 条记录:1.mhtml、2.html、3.html、4.html。底部汇总显示“记录数:4”,说明当前任务中共有 4 个待转换文件。
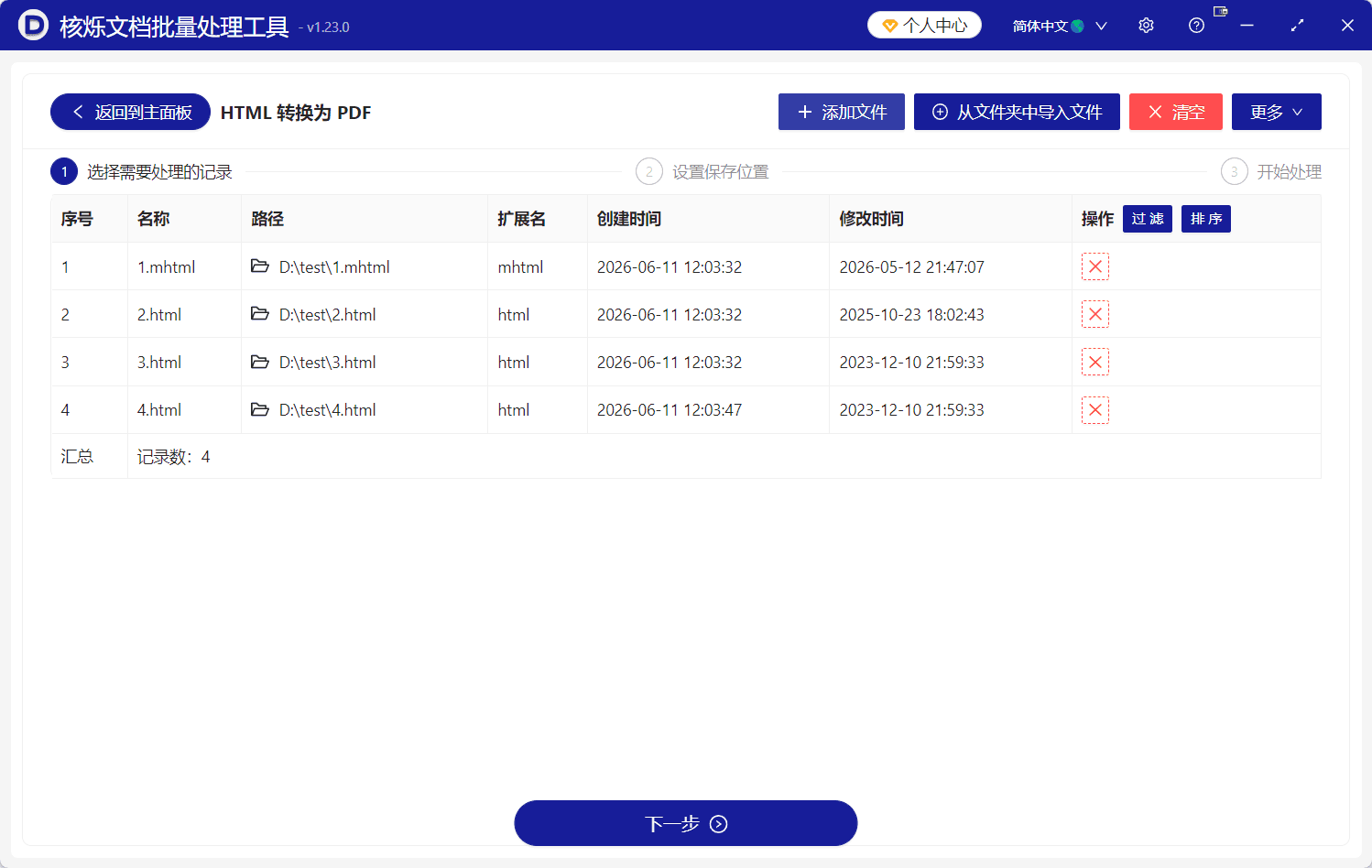
这一步需要重点检查三项内容:第一,看“名称”是否都是本次要转换的网页文件;第二,看“路径”是否来自正确的文件夹,例如截图中的 D:\test\;第三,看“扩展名”和底部“记录数”是否符合预期。批量处理前做好核对,可以避免把无关文件一起转换,也能避免漏掉重要网页文件。
第三步:移除不需要的记录或重新导入
如果导入后发现某个文件不属于本次任务,可以在列表右侧“操作”栏中使用删除图标移除该记录。若整个列表导入错误,也可以点击顶部“清空”按钮,然后重新添加文件或从文件夹导入。
这个步骤看似简单,但对批量转换很重要。因为批量任务一旦开始,软件会按照列表中的记录进行处理。提前整理好任务列表,可以让最终生成的 PDF 更准确,也能减少转换完成后的筛选工作。
第四步:点击“下一步”进入保存位置设置
确认文件列表无误后,点击页面底部的“下一步”。从界面上方的流程提示可以看到,任务分为“选择需要处理的记录”“设置保存位置”“开始处理”三个阶段。当前列表确认完成后,就需要设置 PDF 输出位置。
建议为转换结果单独创建文件夹,例如“网页文件PDF”“HTML转PDF输出”“项目网页归档PDF”等。这样做有两个好处:一是避免 PDF 与原始 html、mhtml 文件混在一起;二是方便转换后直接核对文件数量并打包发送。如果处理的是正式资料,还可以按日期或项目名称建立目录,便于后续追溯。
第五步:开始处理并核对PDF结果
保存位置设置完成后,进入“开始处理”阶段。启动处理后,软件会按照任务列表中的网页文件批量生成 PDF。处理完成后,打开输出目录,检查生成的 PDF 文件是否与源文件数量一致,文件名是否对应。
以示例为例,处理前有 4 个网页文件,处理后得到 1.pdf、2.pdf、3.pdf、4.pdf。这样的对应关系非常适合批量核对:只要检查数量和名称,就能快速判断转换结果是否完整。
常见问题与注意事项
1. 为什么不用浏览器逐个打印成PDF?
浏览器打印适合临时处理单个网页,但不适合大量文件。批量网页文件转 PDF 的核心问题是重复劳动太多,而核烁文档批量处理工具可以一次导入多个文件并统一转换,更符合办公效率要求。
2. 导入文件时应选择“添加文件”还是“从文件夹中导入文件”?
如果只转换少量文件,用“添加文件”即可;如果很多网页文件已经集中在一个文件夹中,使用“从文件夹中导入文件”更高效。截图中的任务列表就是批量导入后集中展示的效果。
3. 转换前要不要整理源文件?
建议整理。可以先把需要转换的 html、mhtml 文件放到同一目录,并删除无关文件。这样导入列表时更清晰,也能减少后续检查成本。
4. 如何确认没有漏转?
可以对比处理前的网页文件数量和处理后的 PDF 数量。软件列表底部会显示记录数,转换完成后再查看输出文件夹中的 PDF 数量,通常就能快速完成核对。
5. 输出PDF后还需要保留原HTML文件吗?
建议保留原始网页文件作为备份,尤其是涉及项目资料、业务凭证或重要归档内容时。PDF 便于流转和查看,原 html、mhtml 则可作为源文件留存。
总结:让网页文件转PDF从重复操作变成批量任务
批量将 HTML 网页文件转换为 PDF,真正提升效率的地方在于减少重复动作。过去需要一个个打开网页文件、一个个保存为 PDF;现在只需要在核烁文档批量处理工具中选择“HTML 转换为 PDF”,导入多个 html、mhtml 文件,设置保存位置后统一处理。
对于经常整理网页资料、系统导出页面、离线文档和项目归档文件的用户来说,这种批量处理方式更稳定、更省时,也更便于结果核对。如果你当前文件夹中已经积累了很多网页文件,不妨按照本文流程先整理源文件,再一次性转换为 PDF,让后续归档、发送和打印都更轻松。