本文介绍如何把多个 HTML、MHTML 网页文件批量转换为 TXT 纯文本格式,适合网页资料归档、内容提取、文本检索、数据整理等场景。通过核烁文档批量处理工具的“HTML 转换为 TXT”功能,可以一次导入多个网页文件或整个文件夹,按向导完成保存位置设置和批量处理,避免逐个打开网页复制粘贴,大幅减少重复操作。
在日常办公中,很多资料会以 HTML、MHTML 网页文件的形式保存下来,例如网页备份、系统导出的页面、历史资料归档文件等。如果只是想提取其中的文字内容,用浏览器逐个打开再复制到记事本,不仅耗时,而且容易遗漏。本文要解决的问题就是:如何批量将很多 HTML 网页文件转换为 TXT 纯文本格式。
下面以办公软件“核烁文档批量处理工具”为例,介绍从选择功能、导入文件到批量转换的完整操作流程。该工具的核心价值是批量处理文件,减少重复劳动,适合需要一次性处理大量文档、网页、文本文件的办公场景。
适用场景
HTML 批量转换 TXT 适合以下几类常见办公需求:
- 网页资料归档:将保存下来的 .html、.mhtml 网页文件统一转换为 .txt,便于长期保存和快速打开。
- 内容提取整理:从多个网页文件中提取文字内容,用于后续编辑、校对、整理或导入其他系统。
- 全文检索:TXT 纯文本体积小、结构简单,适合用搜索工具批量检索关键词。
- 减少重复操作:避免逐个打开 HTML 文件、手动复制、粘贴、另存为 TXT 的低效流程。
- 兼容多种网页文件:从截图中的文件列表可以看到,待处理文件包含 html、mhtml 等扩展名,适合批量处理常见网页保存格式。
效果预览:处理前和处理后
处理前:多个 HTML / MHTML 网页文件
处理前,文件夹中是多个网页文件,例如 1.html、2.mhtml、3.html、4.html。这类文件通常需要通过浏览器打开,里面可能包含网页结构、样式和链接等内容。

处理后:生成对应的 TXT 纯文本文件
批量转换完成后,会得到对应的 TXT 文件,例如 1.txt、2.txt、3.txt、4.txt。转换后的文件可以直接用记事本、Notepad++ 或其他文本编辑器打开,更适合做文字整理、资料归档和关键词检索。
也就是说,原来需要逐个处理的网页文件,可以通过一次批量操作转换为纯文本格式,显著提升办公效率。

操作步骤:批量将 HTML 网页文件转换为 TXT
步骤一:进入“文本工具”,选择“HTML 转换为 TXT”
打开“核烁文档批量处理工具”后,在左侧功能分类中选择文本工具。在右侧工具列表中找到并点击“HTML 转换为 TXT”。
该功能卡片的说明为批量将 HTML 文件转换为 TXT 纯文本格式,正对应本文要完成的网页文件转纯文本需求。进入该功能后,软件会打开专门的处理向导页面。
步骤二:添加需要转换的 HTML 文件
进入“HTML 转换为 TXT”页面后,页面顶部可以看到添加文件、从文件夹中导入文件、清空、更多等操作按钮。
- 如果只需要处理几个指定文件,可以点击添加文件,手动选择要转换的 HTML 或 MHTML 文件。
- 如果文件数量较多,并且集中放在同一个文件夹中,可以点击从文件夹中导入文件,一次性导入文件夹内的网页文件。
- 如果导入错误,可以点击清空重新选择文件。
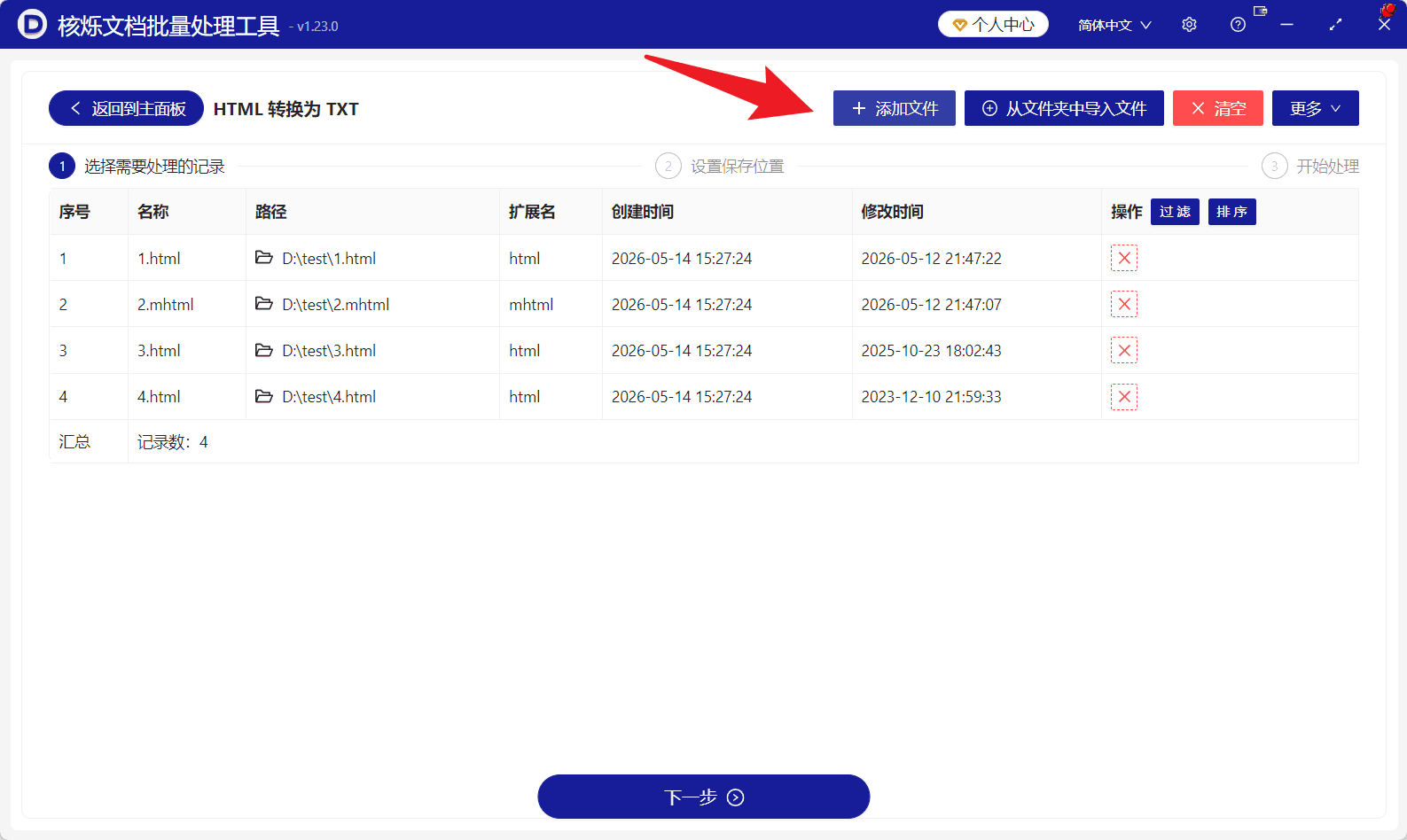
导入后,文件会出现在列表中。列表包含序号、名称、路径、扩展名、创建时间、修改时间、操作等信息,便于在转换前核对文件是否完整。
步骤三:检查待处理文件列表
在文件列表中,可以看到示例文件包括 1.html、2.mhtml、3.html、4.html,路径位于 D:\test\ 目录下,扩展名分别显示为 html、mhtml 等。页面底部还会显示记录数,例如记录数为 4,表示当前已导入 4 个待转换文件。
这一步的目的,是确认待处理文件没有选错、没有遗漏。如果某个文件不需要转换,可以使用该行右侧的删除操作将其移出列表。页面中还提供了过滤和排序按钮,可用于在文件较多时辅助查看和整理列表。
步骤四:点击“下一步”,设置保存位置
确认文件列表无误后,点击页面底部的下一步。从页面流程可以看到,当前任务分为三个阶段:选择需要处理的记录、设置保存位置、开始处理。
进入第二步后,根据软件提示设置转换后 TXT 文件的保存位置。建议选择一个单独的输出文件夹,用来存放转换后的 TXT 文件,避免与原 HTML 文件混在一起,便于后续检查和归档。
步骤五:开始批量处理并查看结果
保存位置设置完成后,继续进入开始处理阶段。软件会按照导入列表批量执行 HTML 转 TXT 操作,将多个网页文件转换为对应的 TXT 纯文本文件。
处理完成后,打开保存目录即可查看生成的 .txt 文件。通常情况下,文件名会与原网页文件相对应,例如 1.html 转换后得到 1.txt,便于快速对照原文件和输出结果。
常见问题与注意事项
1. HTML 转 TXT 后,网页样式还会保留吗?
TXT 是纯文本格式,主要用于保存文字内容,不适合保留网页中的排版、图片、CSS 样式、脚本效果等。如果需要保留网页版式,应考虑转换为 PDF、Word 或其他文档格式;如果目标是提取文字内容,TXT 更轻量、更方便检索。
2. 可以同时处理 html 和 mhtml 文件吗?
从导入列表可以看到,示例中包含 .html 和 .mhtml 文件,并在扩展名列中分别显示。实际操作时,建议先将需要转换的网页文件统一放入同一文件夹,再通过“从文件夹中导入文件”批量添加,处理效率更高。
3. 文件很多时如何确认是否导入完整?
导入后先查看列表底部的记录数,再结合文件名称、路径和扩展名进行核对。如果文件数量较大,可以使用页面中的过滤、排序功能辅助检查,避免漏选或误选。
4. 转换前是否需要备份原文件?
建议保留原始 HTML 文件。TXT 文件更适合保存文字内容,但原网页文件可能包含结构、链接、图片或其他页面信息。将原文件和转换结果分别存放,有利于后续追溯。
5. 为什么建议批量转换,而不是手动复制粘贴?
如果只有一两个网页文件,手动处理还能接受;但当文件数量达到几十、几百个时,逐个打开、复制、粘贴、保存会非常耗时。使用办公软件的批量处理功能,可以把重复操作交给工具完成,减少人工错误并节省大量时间。
总结
批量将 HTML 网页文件转换为 TXT 纯文本,核心价值在于快速提取网页文字内容,方便归档、检索和后续编辑。通过核烁文档批量处理工具,只需要进入“文本工具”中的“HTML 转换为 TXT”,导入多个 HTML、MHTML 文件,设置保存位置并开始处理,就能一次性生成对应的 TXT 文件。
如果你经常需要整理网页资料、处理系统导出的 HTML 页面,或者希望把大量网页文件转换成可检索的纯文本,建议直接使用批量转换流程,避免重复劳动,让文件处理更加高效、规范。