当文件夹名称中间包含不同的临时字段时,使用查找替换往往不够准确,因为每个中间字段都不一样。更适合的方法是按左侧文本和右侧文本定位,批量删除两者之间的所有内容。本文结合核烁文档批量处理工具截图,演示从选择功能、添加文件夹、设置 START 与 _END 边界,到执行处理并查看结果的完整流程。
很多用户在整理文件夹时,会遇到一个看似简单但非常耗时的问题:大量文件夹名称中都有一段不需要的中间字段,而且每个字段内容还不相同。比如有的叫 tempFiles,有的叫 debugInfo,有的是 2024Draft、sampleChunk、oldVersion、batch001。此时普通的查找替换并不好用,因为你不可能为每一个不同字段都单独设置替换规则。更高效的方法是按左右文本定位:找到固定的左边文本 START,再找到固定的右边文本 _END,然后批量删除它们之间的所有内容。
本文将通过核烁文档批量处理工具的实际界面,介绍如何完成这一操作。作为面向办公场景的批量处理软件,它的价值在于把重复性的文件、文件夹和文档处理任务集中起来,用规则替代人工操作。对于批量删除文件夹名称中的中间字段,这种方式尤其适合数量多、命名结构相似但中间内容不同的目录。
适用场景:为什么按左右文本删除比逐个替换更适合
如果所有文件夹名称里要删除的文本完全相同,例如都包含“_old_”,那么普通查找替换就可以解决。但在很多真实办公场景中,要删除的部分并不固定。一个项目目录可能叫 Project_START_alpha_END_Report,另一个可能叫 Photo_START_rawSet_END_Edited,还有一个可能叫 Notes_START_privateText_END_Public。它们的共同点不是中间字段相同,而是中间字段左右两侧有相同的标识。
按左右文本删除的优势就在这里:用户不需要关心中间到底是什么,只要告诉软件从哪里开始定位、到哪里结束定位。示例中,左侧文本是 START,右侧文本是 _END。软件会在每个文件夹名称中寻找这两个边界,并把中间的内容删除。这样,无论中间是英文、数字、版本号、草稿说明还是临时备注,都能按同一规则处理。
这种方法适用于资料归档、项目目录清洗、客户文件夹规范化、设计版本整理、导出目录二次命名等场景。它也适合与其他办公文件管理工作配合使用,例如整理 Word 文档 docx、doc 文件、Excel 报表、PDF 资料和图片素材目录时,先把文件夹结构清理规范,再进行后续分类和备份。
效果预览:处理前中间字段杂乱且内容不同
处理前的截图展示了一批需要清理的文件夹。每个名称中都包含 START 与 END,但两者之间夹着不同文本。例如 Backup_START_tempFiles_END_Final、Data_START_sampleChunk_END_Clean、Invoice_START_batch001_END_Paid、Task_START_removeThis_END_Done。红色标注的位置正是要删除的中间字段。
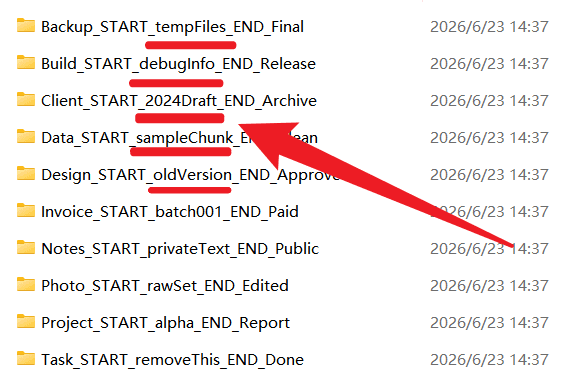
这些中间字段在项目进行过程中可能有意义,但到了归档阶段往往会干扰命名规范。名称越长,用户越难快速识别文件夹的核心含义;字段越不统一,后续搜索和排序越不方便。手动处理不仅慢,还容易因为视觉疲劳造成错误。因此,将这类任务交给批量处理工具更符合办公效率需求。
效果预览:处理后批量保留统一结构
处理后,所有文件夹名称都变成了更统一的格式。中间的 tempFiles、debugInfo、2024Draft、removeThis 等字段已经消失,但 START、END 以及名称前后的业务信息仍然保留。例如 Client_START_END_Archive、Invoice_START_END_Paid、Photo_START_END_Edited。
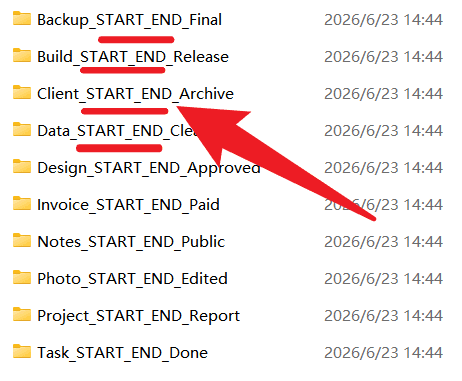
从结果可以看出,本次操作不是删除某一个固定单词,而是删除两个指定文本之间的动态内容。对于大量文件夹名批量删除中间字段来说,这种结果更稳定,也更符合规则化整理的要求。
操作步骤:从功能选择到规则设置完整说明
步骤 1:选择文件夹名称下的删除文本功能
启动核烁文档批量处理工具后,在左侧导航中找到“文件夹名称”。点击后,右侧会显示与文件夹命名相关的多个功能卡片。本次任务要删除文件夹名称中的一段文本,因此选择“删除文件夹名称中的文本”。截图中该功能卡片位于文件夹名称分类下,说明它是专门用于批量处理文件夹名的功能。
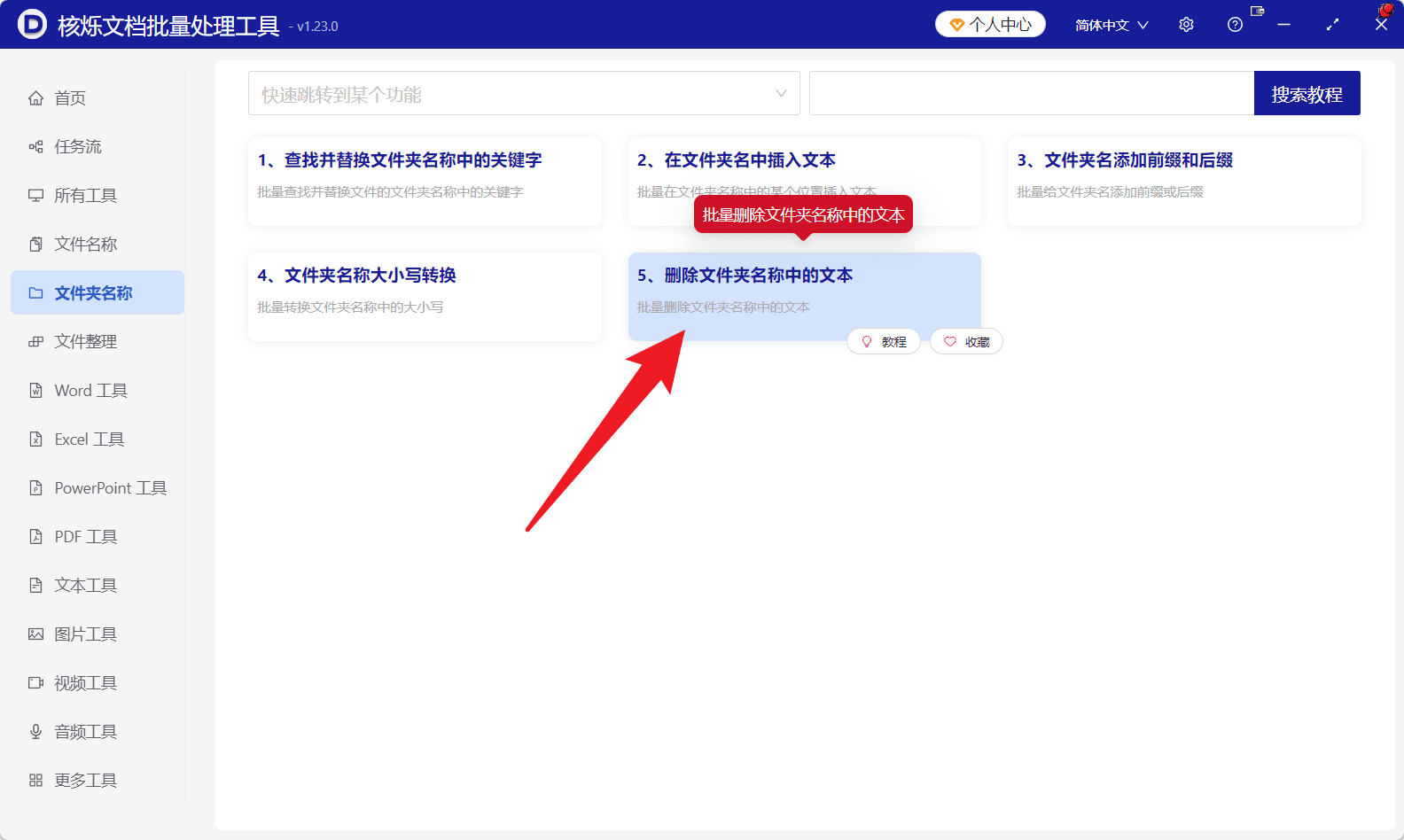
这一步的目的,是保证后续规则作用在文件夹名称上,而不是作用在文件内容或某类文档上。核烁文档批量处理工具中还包含 Word 工具、Excel 工具、PDF 工具、图片工具等分类,用户在操作时应根据处理对象选择对应模块。如果要批量修改的是目录名,就应使用“文件夹名称”相关功能。
步骤 2:导入要处理的文件夹并查看列表
进入功能页面后,当前步骤为“选择需要处理的记录”。点击“添加文件夹”,把需要改名的目录添加到软件中。添加完成后,列表会显示每个文件夹的名称和路径,并在底部汇总记录数。示例中已经导入 10 个文件夹,说明这 10 个目录都将参与后续批量规则处理。
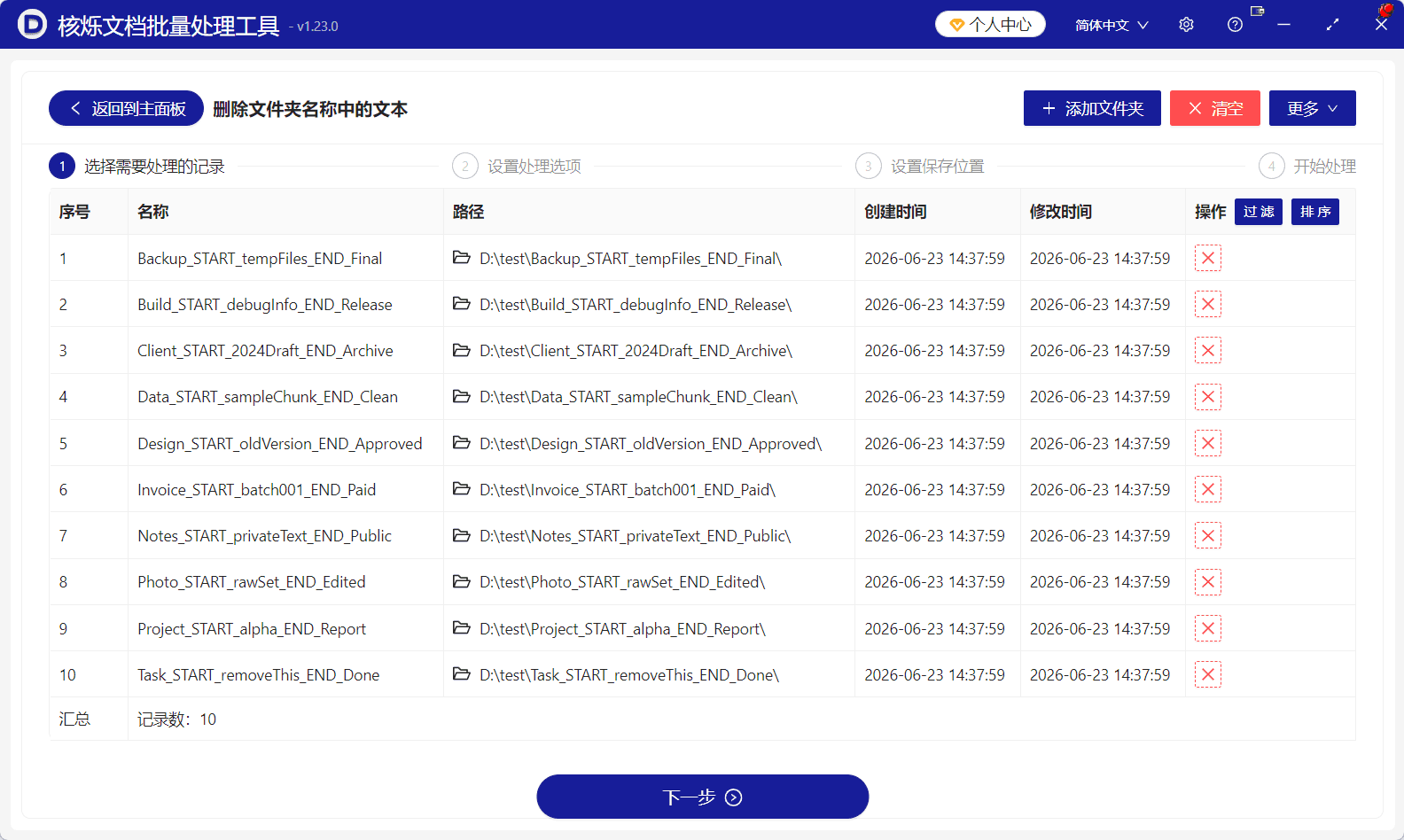
在这里,用户应重点检查名称列。确认每个待处理文件夹都具备 START 和 _END 这两个边界。如果某些文件夹命名结构不同,建议先从列表中移除,避免执行后结果不一致。表格右侧的操作列提供了移除单条记录的入口,页面顶部也可以看到“清空”等按钮,用于重新整理处理列表。
批量处理的核心原则是先确定范围,再设置规则。范围越准确,最终结果越可控。尤其是在处理工作盘、共享目录或客户资料时,不建议不检查就直接执行。
步骤 3:选择按两个文本之间删除,并填写 START 与 _END
点击“下一步”进入“设置处理选项”。在操作类型中选择“两个文本之间的所有内容”。随后在“左边的文本”输入框中填写 START,在“右边的文本”输入框中填写 _END。截图中红色标注强调了这一设置位置。
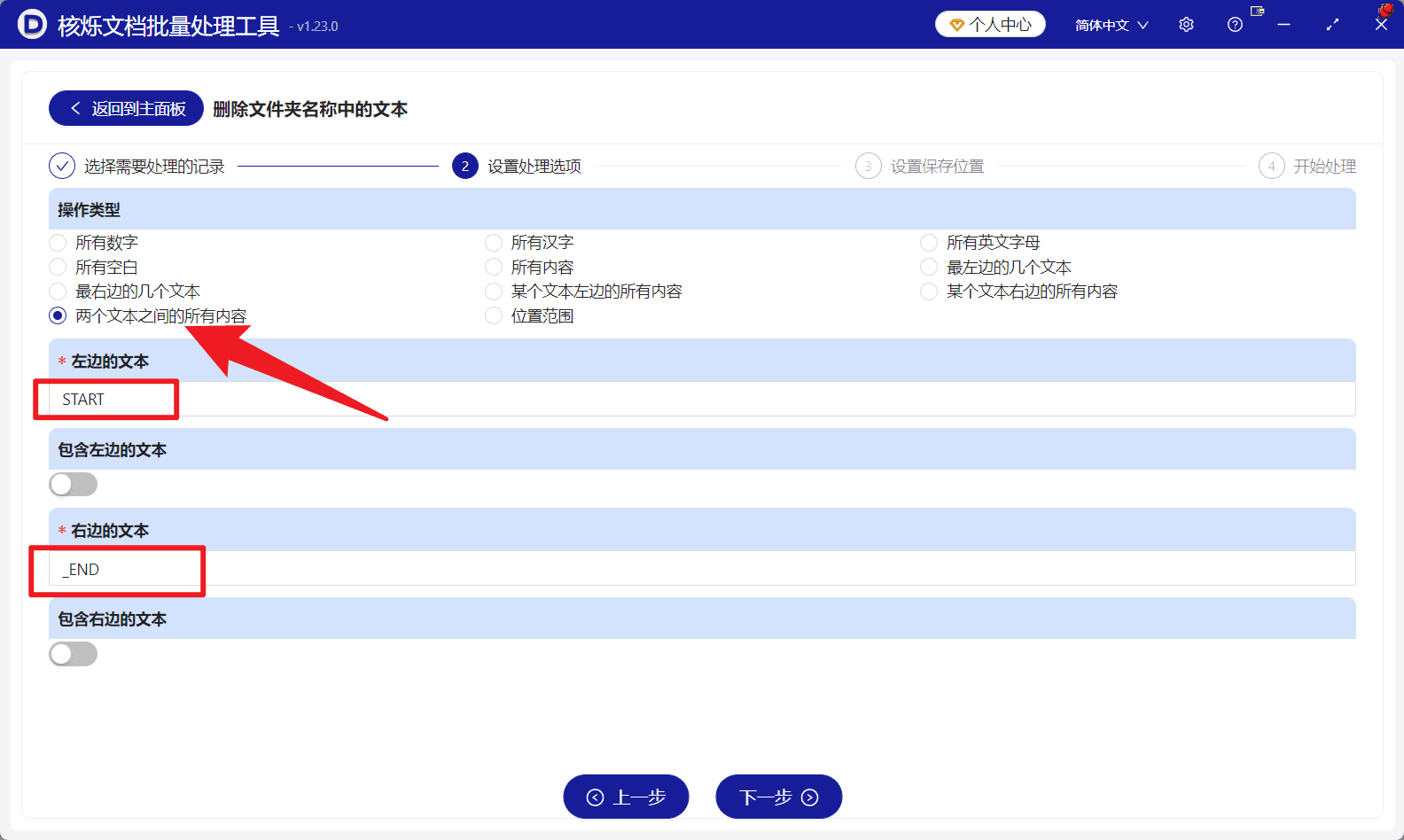
为什么右边文本要写成 _END?以 Build_START_debugInfo_END_Release 为例,START 后面有一个下划线,debugInfo 后面又连接 _END。如果只把右边文本写成 END,删除后的分隔符可能不符合预期;写成 _END 后,要删除的范围包含 START 后面的下划线和中间变量,最终留下 START_END,格式更自然。
同时,界面中可以看到“包含左边的文本”和“包含右边的文本”开关。当前示例要保留 START 和 END,因此不要开启包含边界文本。保持关闭时,软件只删除两个边界之间的内容,而不会删除边界本身。这一点决定了处理后的名称是否还能保留 START_END 结构。
步骤 4:进入保存位置和开始处理流程
完成规则设置后,继续点击“下一步”。页面流程显示后续步骤为“设置保存位置”和“开始处理”。在开始处理之前,建议再次核对三个关键信息:待处理记录数量是否正确,左边文本是否为 START,右边文本是否为 _END,包含边界文本的开关是否保持关闭。
确认无误后执行处理。处理完成后,可以在文件夹所在位置查看名称变化。若看到原本不同的中间字段都被删除,并统一变成 START_END 结构,就说明规则执行成功。
常见问题或注意事项
1. 中间字段包含数字、英文或多个单词是否影响处理
一般不影响。该操作类型依据左右边界定位,而不是识别中间字段的具体内容。只要中间字段位于 START 和 _END 之间,就可以被删除。示例中的 2024Draft、batch001、rawSet 都属于这种情况。
2. 左右文本应该怎么选择
左右文本应选择在每个文件夹名称中都稳定出现的部分。左边文本建议选择要保留区间左侧的固定字符,右边文本建议包含必要的分隔符。例如本例中右边文本选择 _END,就是为了控制删除后的下划线数量。实际使用时,可以先观察几条典型名称,再决定边界。
3. 如果处理结果不是预期怎么办
多数情况下,问题来自边界文本输入不准确,例如少写下划线、多写空格、大小写不一致,或错误开启了包含边界文本。建议先用少量文件夹测试规则,确认结果正确后再对大量目录执行。
4. 这种方法和查找替换有什么区别
查找替换适合删除固定文本;按两个文本之间删除适合删除不固定文本。本文场景中,每个文件夹的中间字段都不同,所以使用左右边界定位更省事、更准确。
总结:大量文件夹名中间字段清理应优先使用批量规则
当大量文件夹名中间字段不同,但左右标识一致时,逐个重命名或逐个查找替换都不是高效方案。使用核烁文档批量处理工具,可以通过“删除文件夹名称中的文本”功能,选择“两个文本之间的所有内容”,输入 START 和 _END,快速删除中间变量并保留统一结构。对于经常处理项目资料、客户目录、归档文件夹和办公文档目录的用户来说,这种批量处理方式能减少大量重复劳动,也能降低命名错误。建议在正式执行前先检查记录和边界文本,确认结果后再批量处理,让文件夹管理更加规范、高效。