文件名中固定字符区间往往代表地区、项目、部门或批次信息。本文通过一个txt文件分类示例,说明如何用核烁文档批量处理工具选择“按自定义位置范围内的字符分类”,把第4到第6位字符作为文件夹名称,批量生成LON、NYC、PAR、SYD、TYO等目录,实现高效文件整理。
很多企业和个人在整理资料时,会先给文件制定命名规则,例如用前几位表示编号,中间几位表示类别,后面几位表示流水号。这样的命名方式便于识别,但如果文件仍然全部堆在一个文件夹里,使用起来并不方便。真正高效的做法,是把文件名中的类别字段提取出来,转化为文件夹结构。
本文围绕“批量将很多文件按文件名中的固定范围内的字符分类放到一起”这个办公场景展开。示例文件包括“128LON75957.txt”“233SYD50778.txt”“662PAR30266.txt”等,其中第4到第6位字符是分类代码。通过核烁文档批量处理工具,可以将这个字符区间设置为分类依据,让软件自动完成分文件夹归档。
适用场景:固定字符区间代表业务分类
固定字符区间归档的前提,是文件名具有稳定格式。示例中的格式非常清楚:前三位数字用于区分文件编号,第4到第6位是三位字母代码,后面是数字流水号,扩展名为txt。第4到第6位的LON、NYC、PAR、SYD、TYO并不是随机字符,而是可以用于分类的业务标识。
在实际办公中,这类标识可能代表不同含义:在外贸资料中可能是城市或国家代码,在项目资料中可能是项目简称,在财务资料中可能是账套或部门代码,在仓储资料中可能是库区代码,在研发资料中可能是版本或模块标识。只要分类字段处在固定位置,就可以用“范围”来定义分类规则。
这种方法尤其适合处理大量文件。例如批量整理txt日志、Word报告docx/doc、Excel数据表xlsx/xls、PDF合同、扫描图片、设计素材等。与手工整理相比,使用办公软件批量处理可以减少重复点击、降低错放文件的概率,并让分类标准保持一致。
效果预览:整理前文件虽然有规则但没有分组
从处理前截图可以看到,多个txt文件排列在同一个目录下。红色下划线标出了文件名中的三位字母代码,红色箭头也指向了这一固定字符区域。也就是说,分类依据已经存在,只是还没有被转换成文件夹。
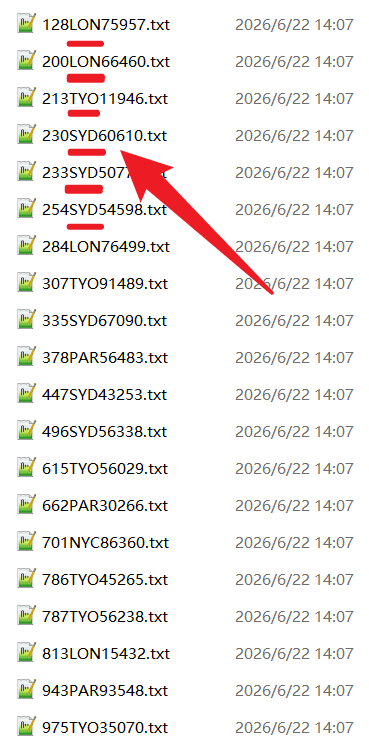
如果继续保持这种混合状态,后续使用会越来越麻烦。例如需要筛选所有PAR文件时,要在文件列表中搜索PAR;需要把SYD文件单独发给同事时,要逐个挑选;如果文件名很多且相似,还可能误选其他类别。文件命名规则只有和文件夹结构结合起来,才能真正提升管理效率。
效果预览:整理后按代码生成独立文件夹
处理后,系统生成了多个分类文件夹,分别是LON、NYC、PAR、SYD、TYO。这些名称不是手动输入的,而是根据文件名第4到第6位字符自动提取得到的。相同代码的文件会被集中放入同一文件夹。

这种结果符合大多数办公归档习惯:文件夹代表分类,文件保留原名称。用户既可以通过文件夹快速定位类别,也可以保留原文件名中的编号和流水号,方便继续追踪来源。
操作步骤:从选择功能到完成归档
步骤一:在文件整理中找到按文件名分类功能
打开核烁文档批量处理工具,在左侧功能栏选择“文件整理”。该软件是面向办公场景的批量处理工具,核心价值在于用规则替代重复手工操作。进入文件整理后,选择“将文件按文件名分类”。
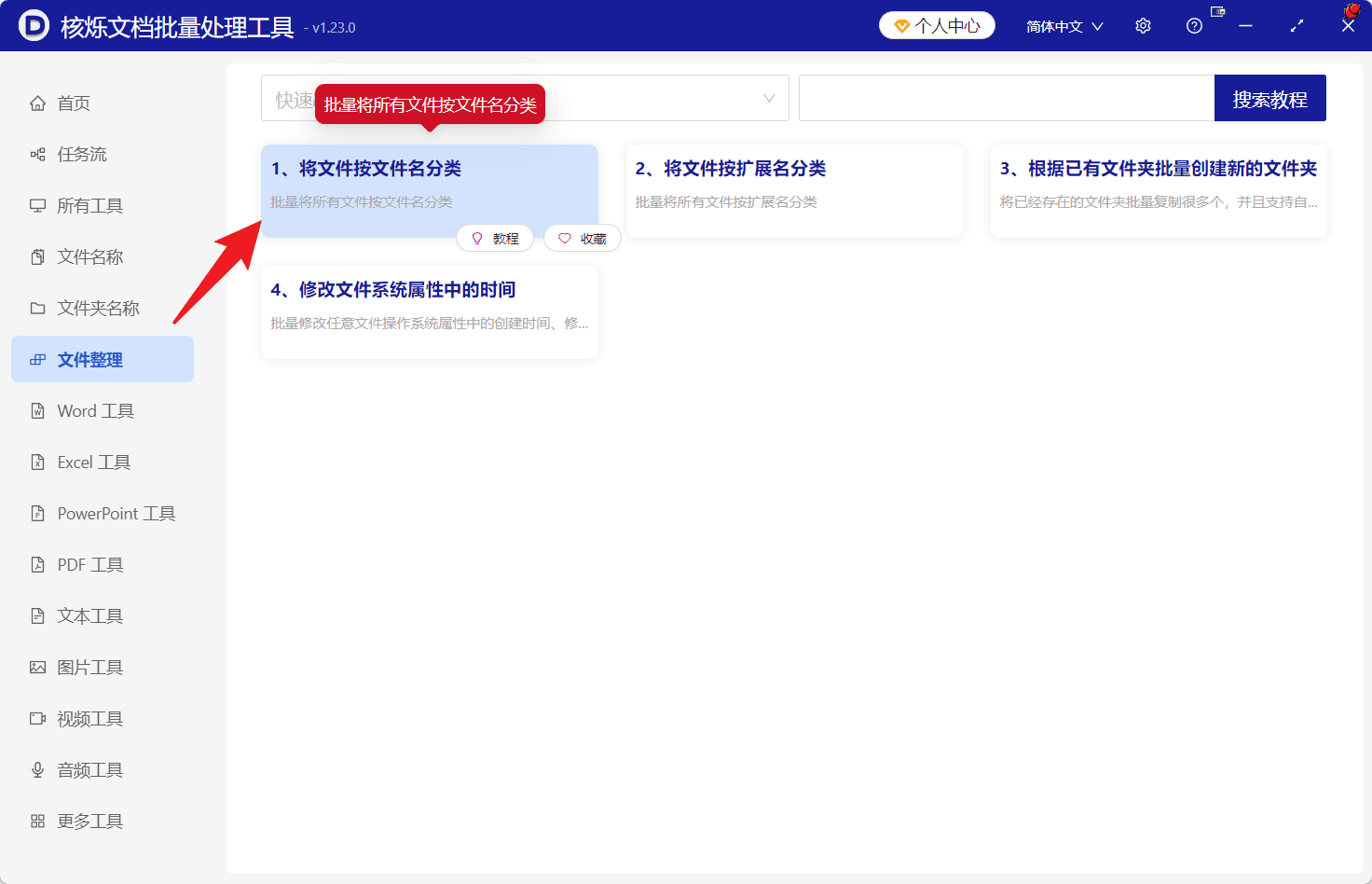
这一步的目的是进入正确的批量归档任务。界面中还可以看到其他整理相关功能,但本次需求不是按扩展名,也不是修改文件时间,而是根据文件名中的固定字符生成分类文件夹,所以应点击“将文件按文件名分类”。
步骤二:把需要处理的文件加入任务列表
进入功能页面后,软件显示四个流程:选择需要处理的记录、设置处理选项、设置保存位置、开始处理。第一步需要导入文件。界面上方提供“添加文件”和“从文件夹中导入文件”,用户可以根据文件存放情况选择。
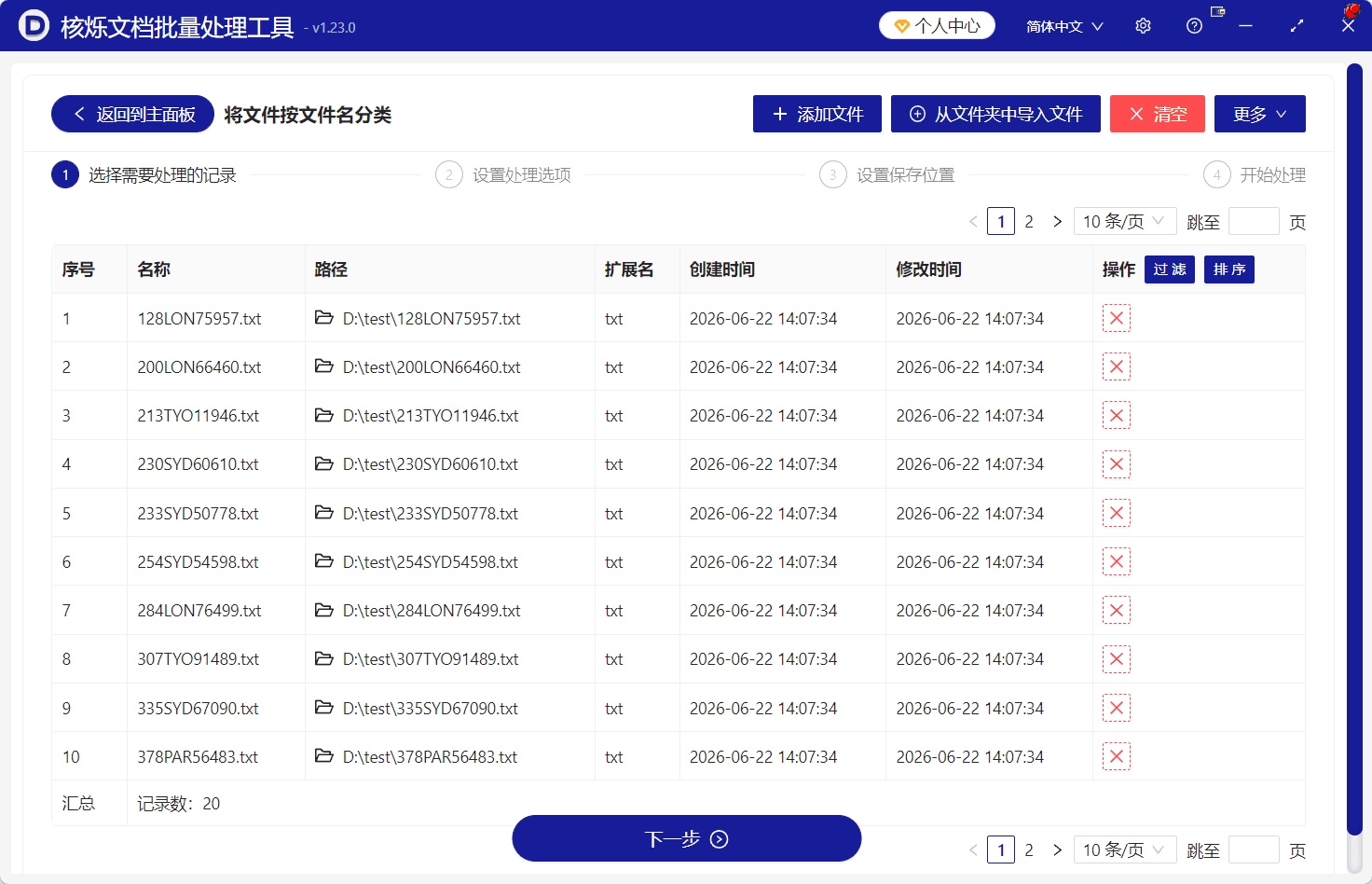
如果待处理文件都位于同一个目录,例如截图中的D:\test\,推荐使用“从文件夹中导入文件”。导入后,表格会显示文件名称、路径、扩展名、创建时间、修改时间等字段。这里可以看到记录数为20,说明当前已有20个文件等待处理。
在点击下一步之前,建议先检查列表中的文件名是否符合预期。比如“128LON75957.txt”的第4到第6位为LON,“230SYD60610.txt”的第4到第6位为SYD。如果列表里混入了命名规则不同的文件,最好先移除,避免生成错误分类。
步骤三:设置分类方式为自定义位置范围
确认文件列表后,点击底部“下一步”,进入处理选项设置。这里是整个操作的关键。由于我们要按文件名固定字符区间归档,所以在分类方式中选择“按自定义位置范围内的字符分类”。
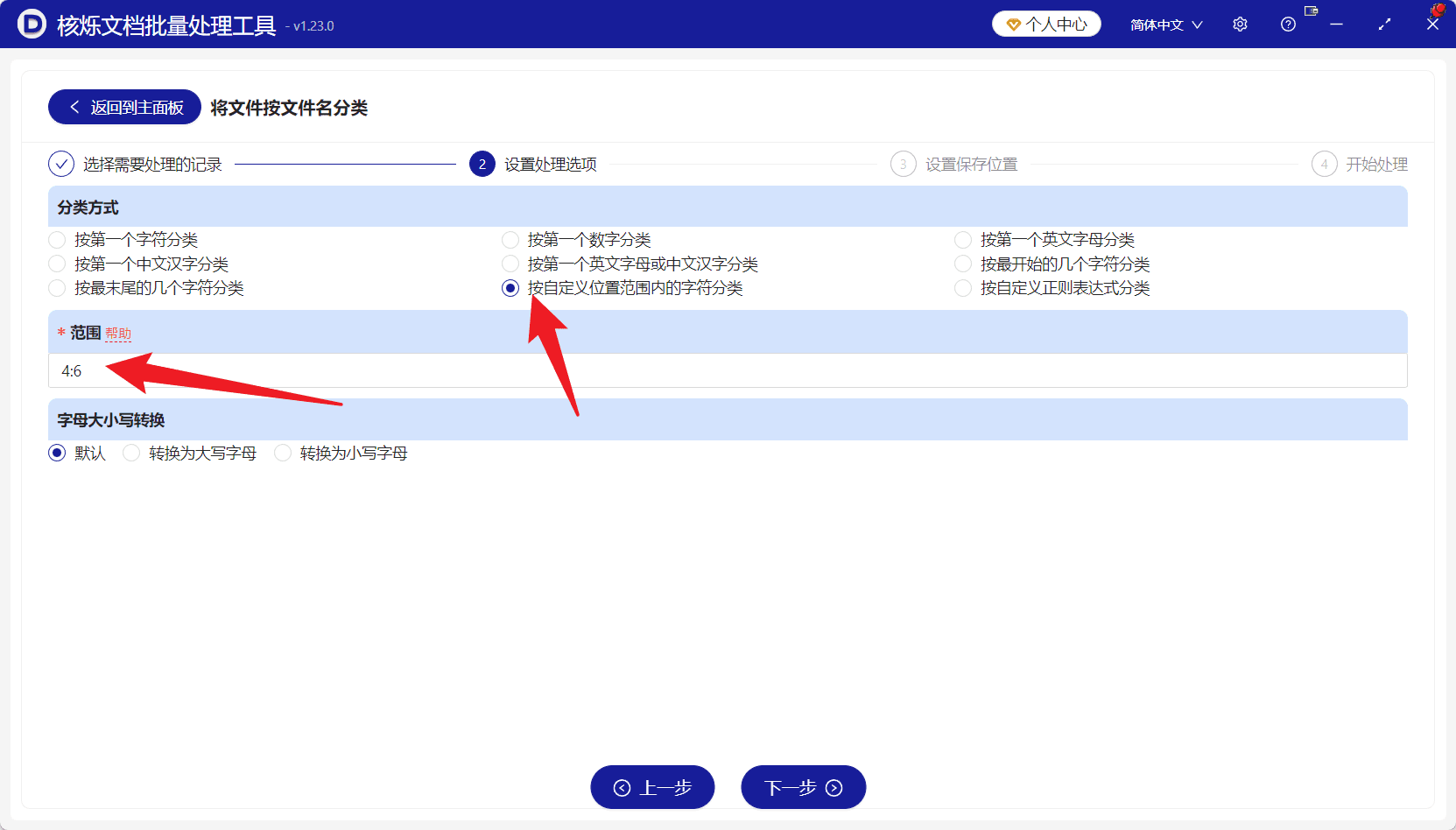
软件界面提供了多种分类方式,例如按第一个字符、按第一个数字、按第一个英文字母或中文字、按末尾几个字符、按最开始的几个字符、按自定义正则表达式等。对于分类字段处在中间位置的文件名,选择“按自定义位置范围内的字符分类”更准确。
步骤四:在范围中输入4:6
选择自定义位置范围后,在“范围”输入框中填写“4:6”。这表示提取文件名第4位到第6位之间的字符作为分类名称。以“975TYO35070.txt”为例,前三位是975,第4到第6位是TYO,因此它会被归入TYO文件夹;以“701NYC86360.txt”为例,第4到第6位是NYC,因此会归入NYC文件夹。
设置范围时要注意,数字位置应与文件名实际结构一致。不要只看某一个文件,而应抽查多个文件,确认所有文件的分类代码都在相同位置。如果有的文件名前缀是两位数字,有的是三位数字,那么第4到第6位可能就不再都是分类代码,这种情况需要先统一文件名规则后再处理。
步骤五:确认字母大小写转换选项
在截图中,“字母大小写转换”区域选择了“默认”。这意味着软件会按文件名中的原始字符生成分类结果。如果文件名里都是大写代码,例如LON、NYC、PAR,保持默认即可。这样处理后得到的文件夹名称也会保持大写,和原文件名一致。
如果团队内部有统一命名要求,建议在批量处理前先确定文件夹名称格式。对于本例,不需要额外转换,因为所有分类代码已经统一为大写。
步骤六:设置保存位置并开始处理
点击“下一步”后,流程会进入“设置保存位置”。建议选择一个新的输出目录,例如专门用于保存分类结果的文件夹。这样即使需要复核,也可以清楚地区分原始文件和处理后的文件夹结构。
最后进入“开始处理”。软件会根据每条文件记录的名称,批量读取第4到第6位字符,自动建立相应文件夹,并将文件按分类放到一起。完成后即可看到LON、NYC、PAR、SYD、TYO等分类文件夹,达到从混合目录到结构化归档的效果。
常见问题或注意事项
1. 为什么不是按前三位数字分类?
分类依据取决于业务需求。示例中文件前三位数字更像编号,每个文件可能都不同;第4到第6位字母代码才是可归类的信息。批量分类时应选择能代表类别的字符区间,而不是简单选择文件名前几位。
2. 如果文件名中有重复代码,会怎样?
重复代码正是分类的目标。只要多个文件第4到第6位相同,它们就会进入同一个分类文件夹。例如多个文件包含SYD,就会集中到SYD文件夹中,便于统一查看和处理。
3. 处理后的文件夹名称从哪里来?
文件夹名称来自你设置范围内提取到的字符。填写“4:6”后,软件会从每个文件名中取第4、第5、第6位字符。提取结果是LON就生成或使用LON文件夹,提取结果是PAR就生成或使用PAR文件夹。
4. 是否适用于非txt文件?
示例使用txt文件,是为了清楚展示文件名规则。实际上,只要软件导入的是文件记录,并且文件名规则一致,docx、doc、xlsx、xls、pdf、png、jpg等办公文件或素材文件也可以按同样方法整理。
5. 批量处理前最重要的检查是什么?
最重要的是检查字符范围是否正确。建议先用几个代表性文件验证,例如LON、NYC、PAR、SYD、TYO各选一个,确认它们的分类代码都位于第4到第6位。确认无误后再处理全部文件。
总结:把文件命名规则转化为可执行的批量整理规则
文件名中的固定字符区间,本质上就是一种隐藏的分类规则。通过核烁文档批量处理工具,用户可以把这条规则直接应用到文件整理中:导入文件、选择按文件名分类、设置自定义范围“4:6”、指定保存位置并开始处理。软件会自动完成建文件夹和归档动作。
对于需要频繁整理大量办公资料的用户来说,这种方式能显著减少重复劳动,避免手动移动文件带来的错误。下次遇到文件名中包含固定位置代码的txt、Word、Excel、PDF或图片文件时,可以优先考虑用批量处理方式完成归档,让文件管理更高效、更规范。