當每個 PDF 檔案都包含產品編號、訂單號或物流單號等唯一的條碼,但是檔案名稱卻不是和檔案中條碼一樣的內容,在查找和管理檔案的時候就會讓我們耗費更多不必要的時間去確認檔案。特別是在電商或物流行業,PDF 中存在條碼的場景尤為廣泛,一般這種情況下,我們通常都是打開 PDF,檢視條碼後複製其編碼,再關閉檔案,把編號貼上該檔案上進行重新命名,這種手動操作的方式效率低是其次,最主要的問題是檔案非常多時就很容易出現貼上錯誤。
那我應該如何跳過這些重複繁瑣的過程,根據 PDF 檔案中的條碼直接對檔案名稱進行批次重新命名呢?今天教大家三種最方便簡單的方法,無論是本地工具輔助操作或是在線工具處理都能快速學會,看完就能使用。
什麼時候要將 PDF 的檔案名稱修改為檔案中的條碼編號?
更新檔案名稱
在日常工作當中,如果把 PDF 檔案名稱改成檔案裡出現的條碼編號,通常都是為了讓檔案容易識別和管理,很多企業每天都要處理大量的文件,如果檔案名稱沒有條理,很難快速找到對應的內容,比如物流單號、商品單號或訂單號,使用條碼做檔案名稱,相當於每份文件都貼了唯一的身份證,不管在哪裡都能夠快速查到,不會和其它文件混淆。
方便系統識別
系統在匯入檔案時,會根據檔案名稱來自動匹配資料庫中的對應記錄,假如檔案名稱不是條碼編號,系統都無法正確識別,甚至會出現匯入識別、內容不匹配以及資料錯亂等問題。所以我們必須把 PDF 檔案名稱改成檔案裡的條碼編號,才能讓系統順利讀取,就好比把快遞單號寫對,快遞公司才知道包裹屬於誰。
避免人工錯誤
人工處理檔案的時候,如果條碼和名稱不一致,後續的流程就會出現尋找困難、重複處理甚至漏掉的問題,當檔案數量很大,這種風險也會加大。因此將 PDF 檔案名稱改成條碼,能夠讓檔案與它的內容完全一致,讓所有操作人員都能一眼識別,避免手動核對,既降低了工作量,也降低了人為失誤。
根據 PDF 中條碼將檔案重新命名的效果預覽
處理前:
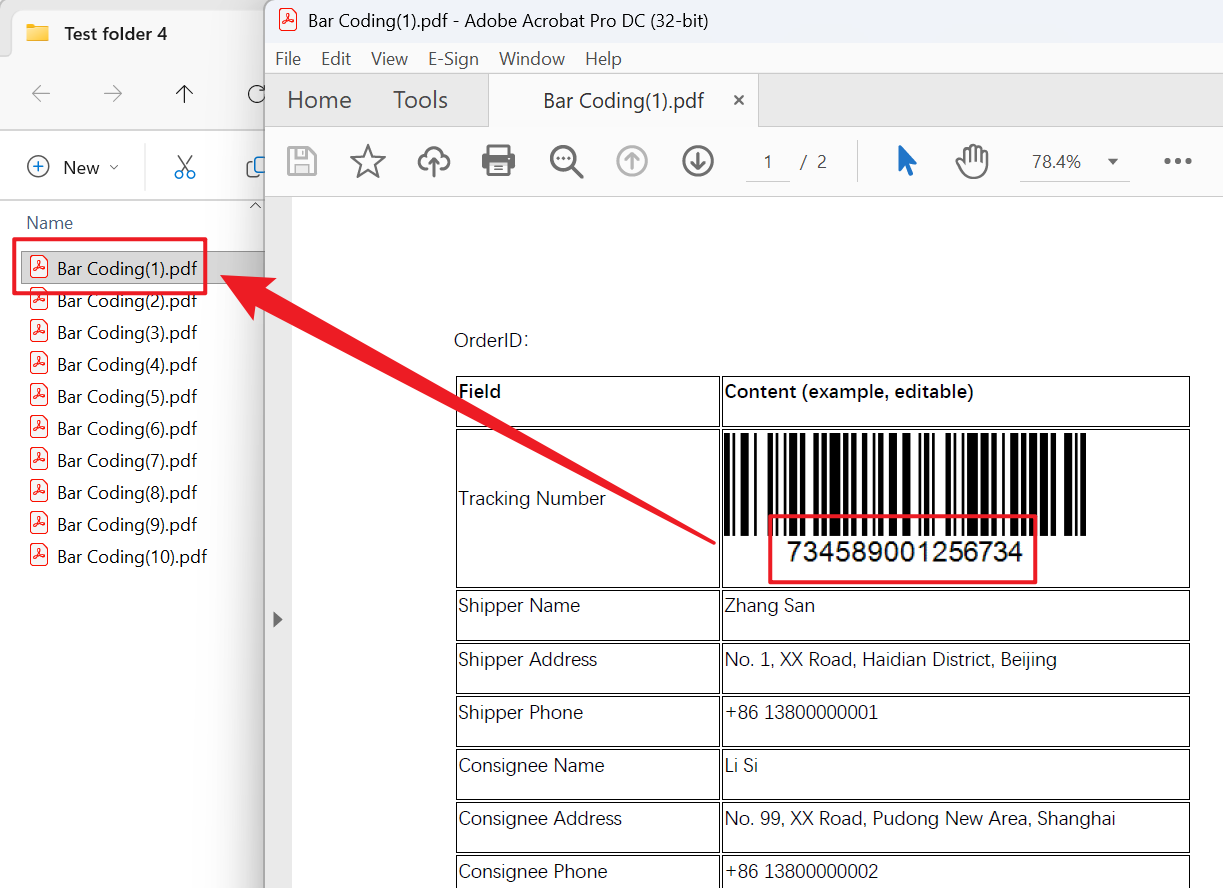
處理後:
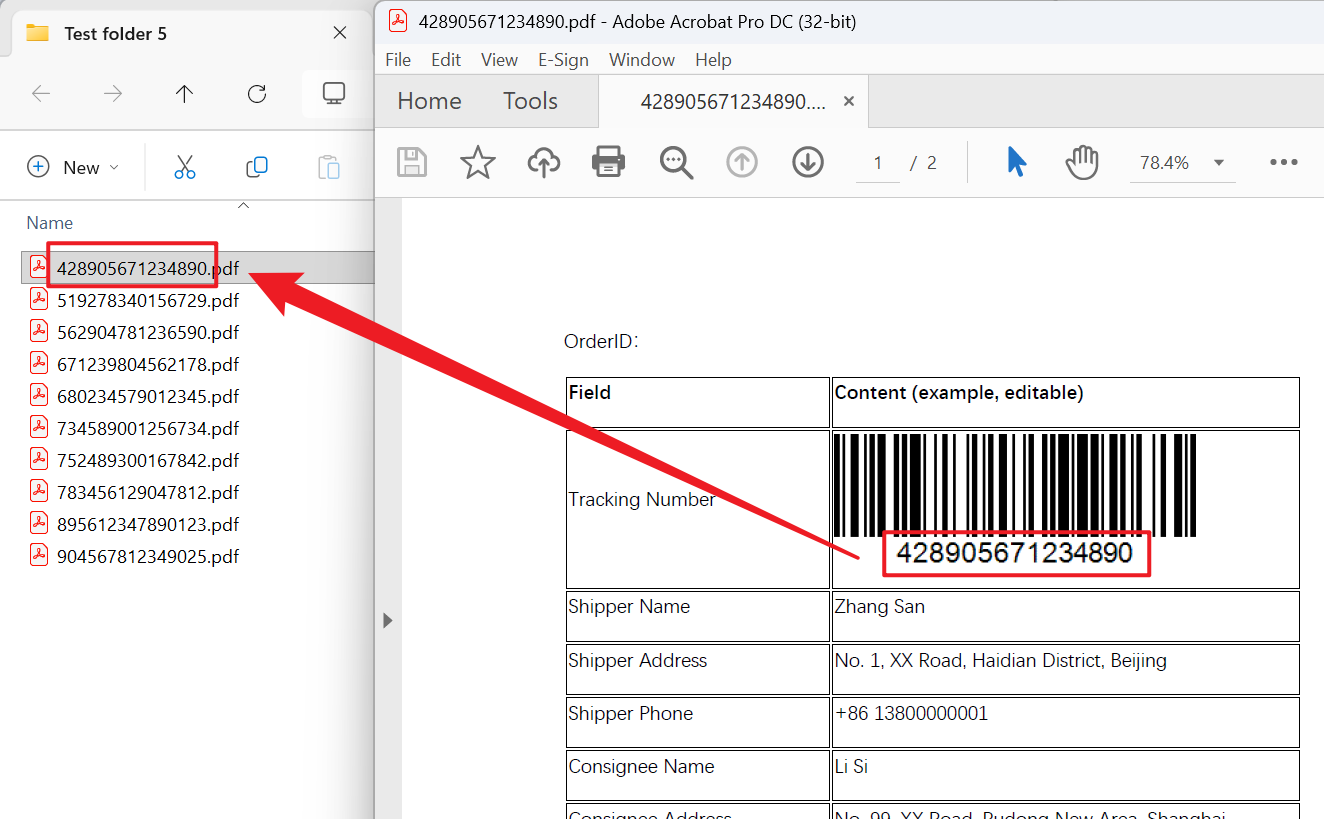
方法一:使用核爍文檔批量處理工具將 PDF 重新命名為文件內條碼編號
推薦指數:★★★★★
優點:
- 功能較為完善,操作簡單易懂,支援大量檔案批次進行處理,並且帶有技術支援,小白也能快速操作。
- 所有檔案都是在本地處理,不含上傳檔案的性質,保護使用者的隱私。
缺點:
- 只能安裝軟體在電腦中操作。
操作步驟:
1、開啟【核爍文檔批量處理工具】,選擇【檔案名稱】-【使用檔案內容重新命名 PDF 檔案】。
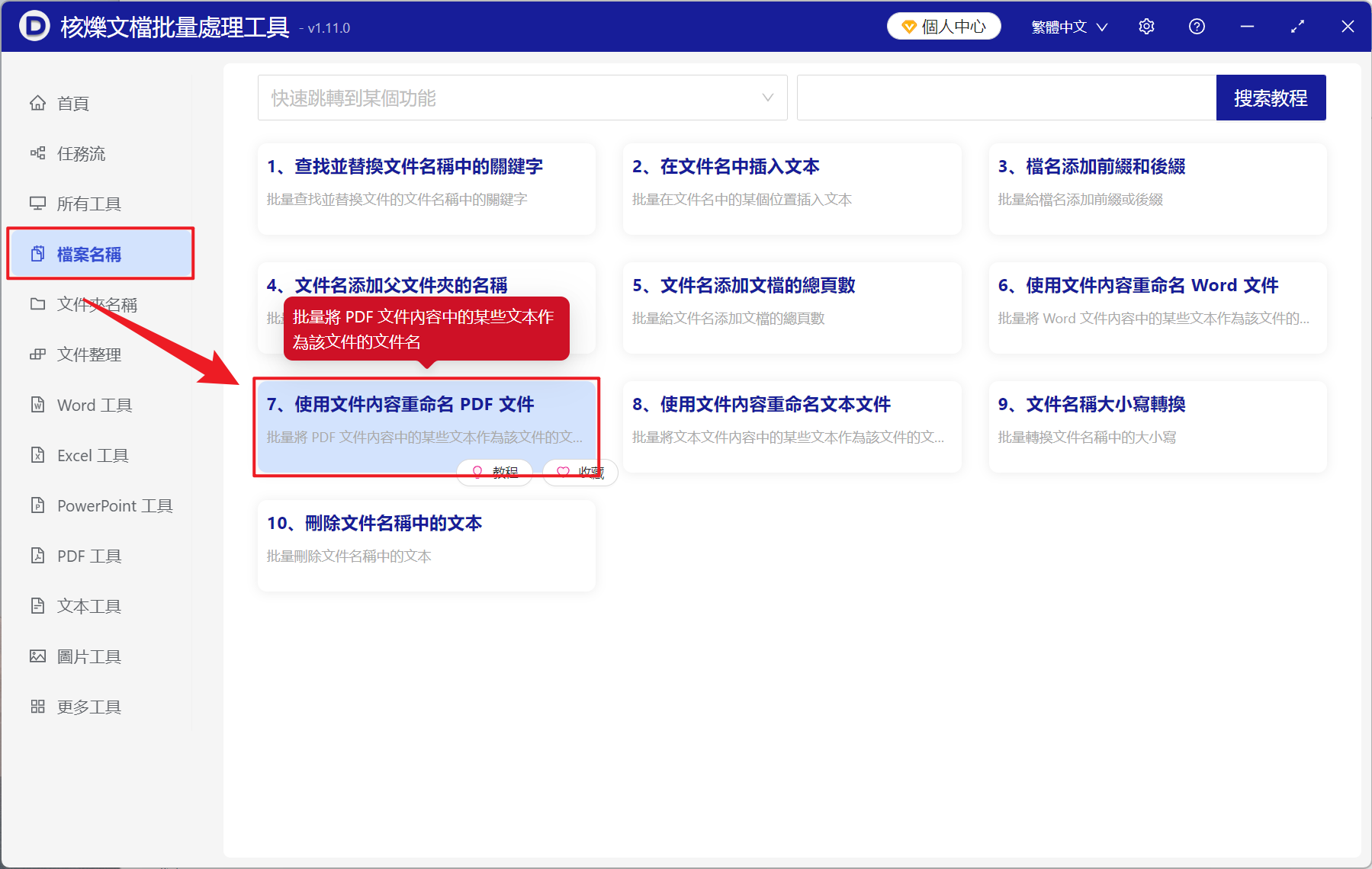
2、在【新增檔案】或【從資料夾中匯入檔案】中選擇一個方式將需要重新命名的 PDF 檔案新增,也支援將檔案拖入下方匯入,確認檔案沒有問題後,點選下一步。
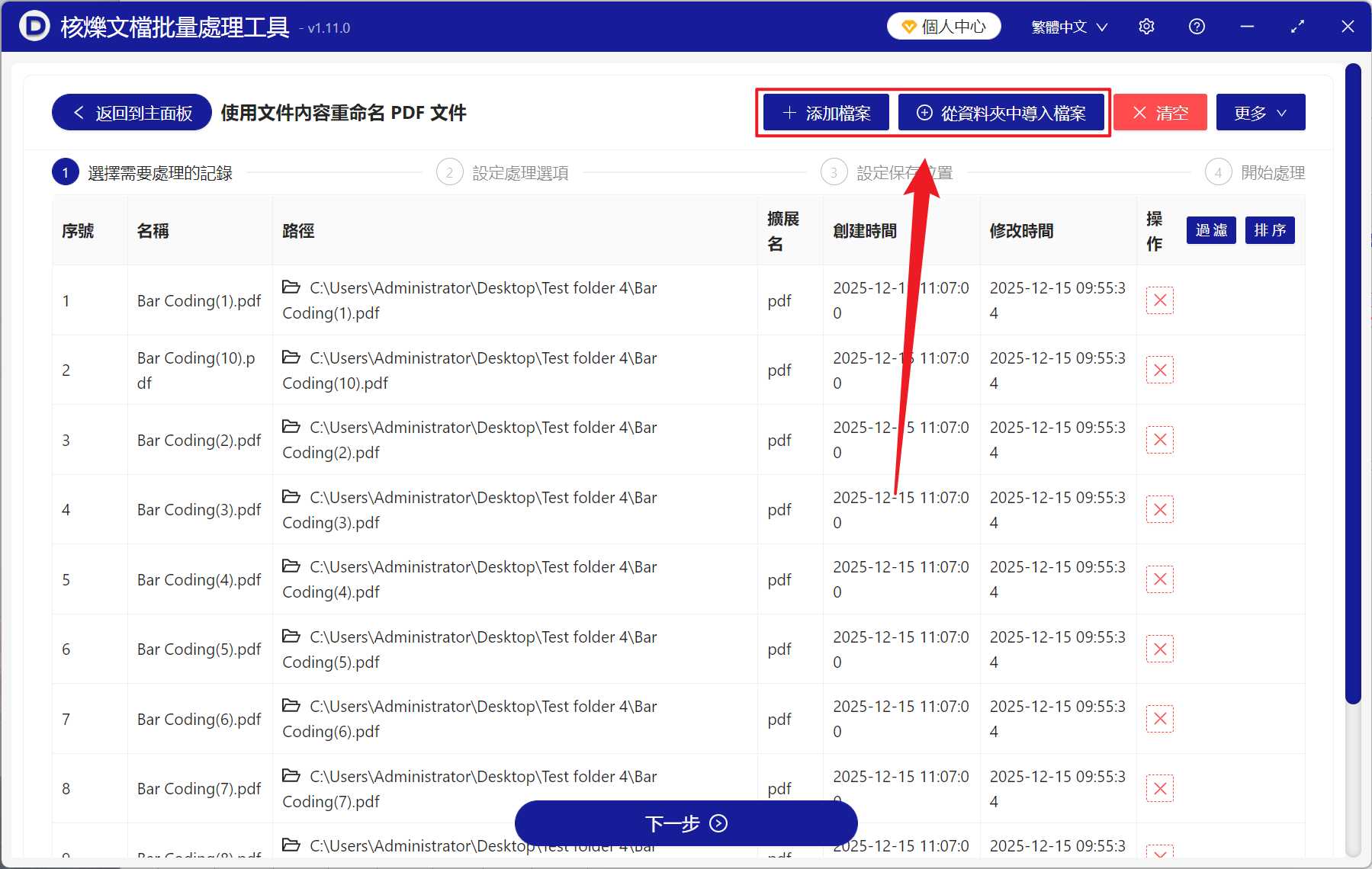
3、進入設定選項介面,在尋找區域選擇【第一個條碼圖片】,在位置選擇【覆蓋整個檔案名稱】,假如需要保留原檔案名稱,可以在檔案名稱左邊或右邊新增條碼編號。最後點選下一步,接著點選瀏覽,選擇新檔案的儲存位置。
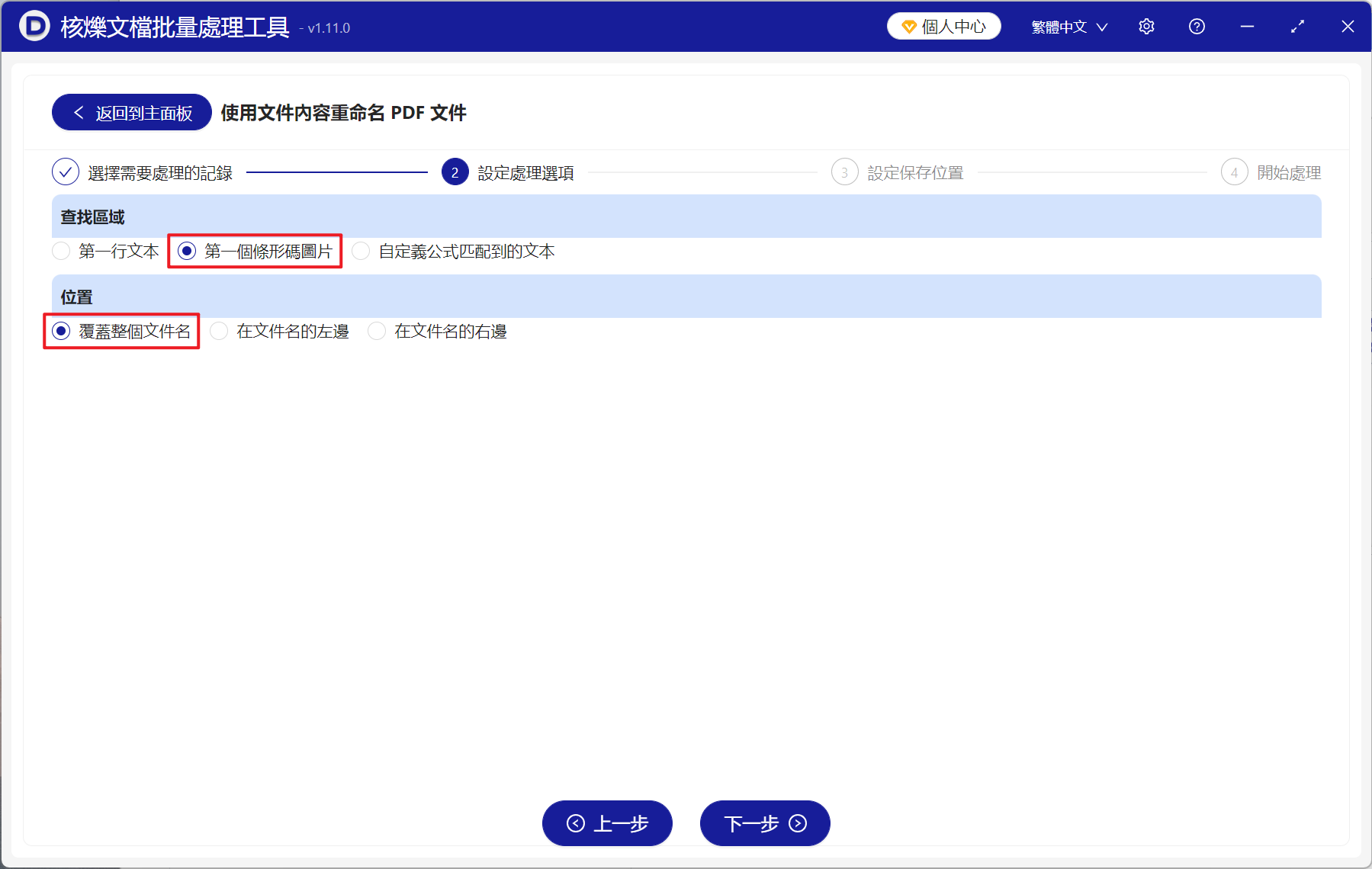
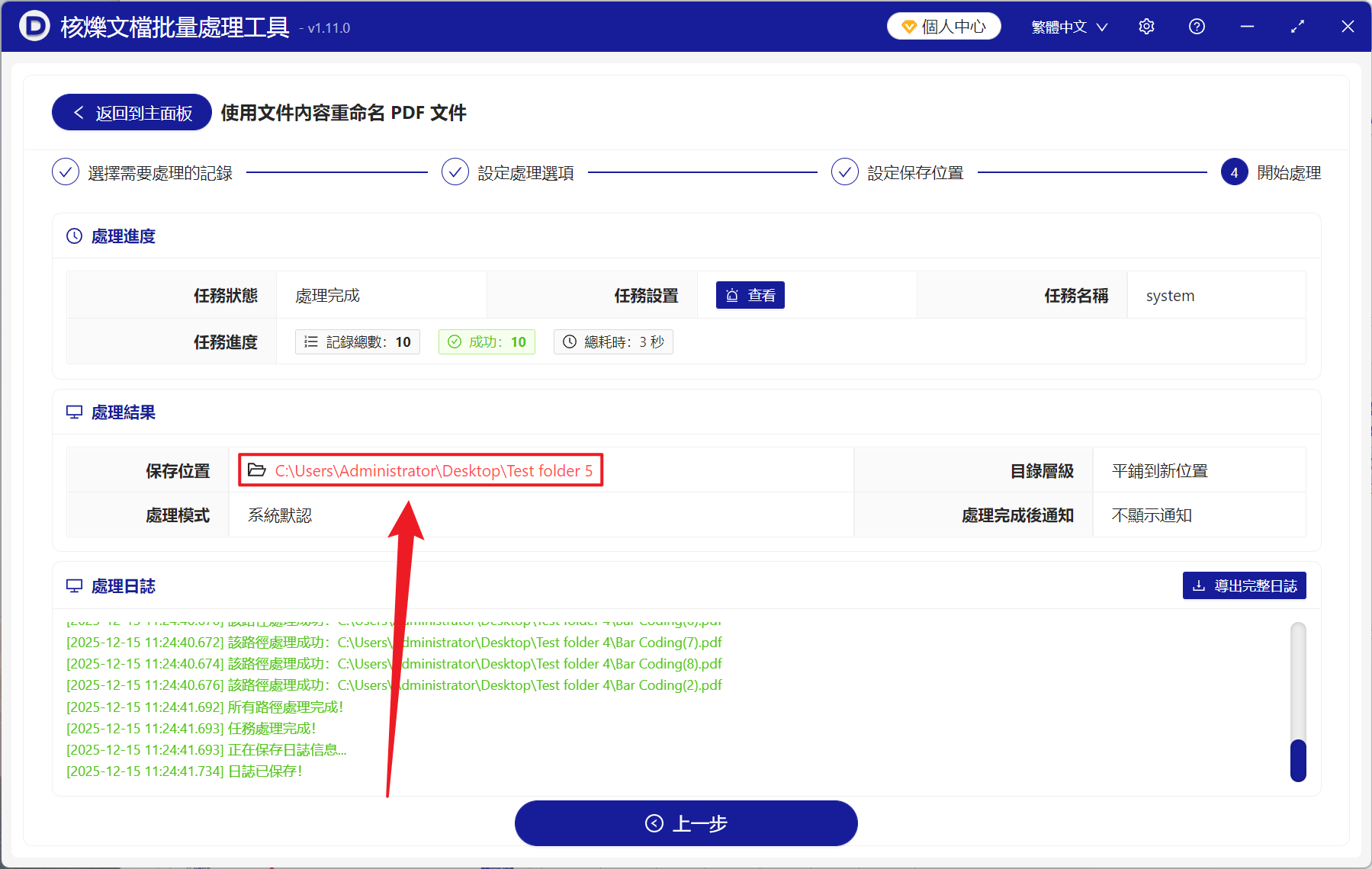
4、等待處理結束之後,點選紅色的路徑即可開啟資料夾,可以看到所有的 PDF 都成功重新命名為文件內的條碼編號。
方法二:使用線上工具識別條碼重新命名 PDF 檔案
推薦指數:★★★☆☆
優點:
- 無需安裝任何軟體,也可以免費使用。
- 隨時隨地都可以操作,行動裝置也能處理。
缺點:
- 無法批次處理多個檔案,需要手動複製貼上。
- 上傳檔案可能會有洩露隱私的風險。
操作步驟:
1、開啟【Online Barcode Reader】網站,上傳 PDF 檔案。
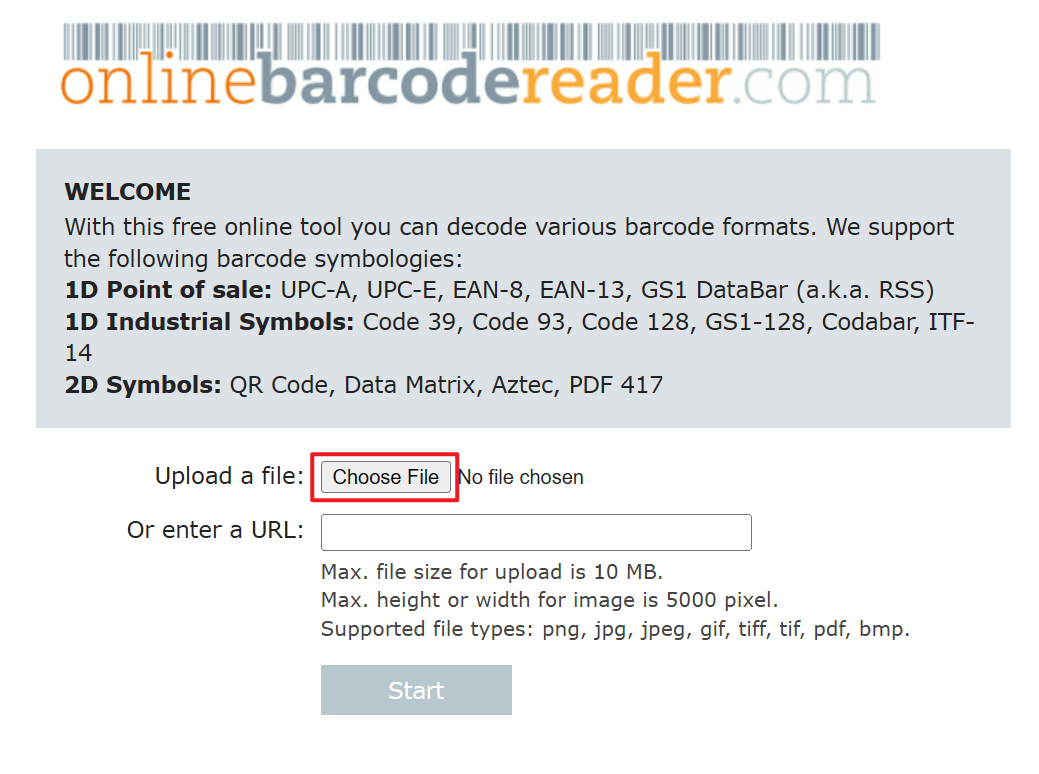
2、等待自動識別完條碼編號,接著複製識別結果。
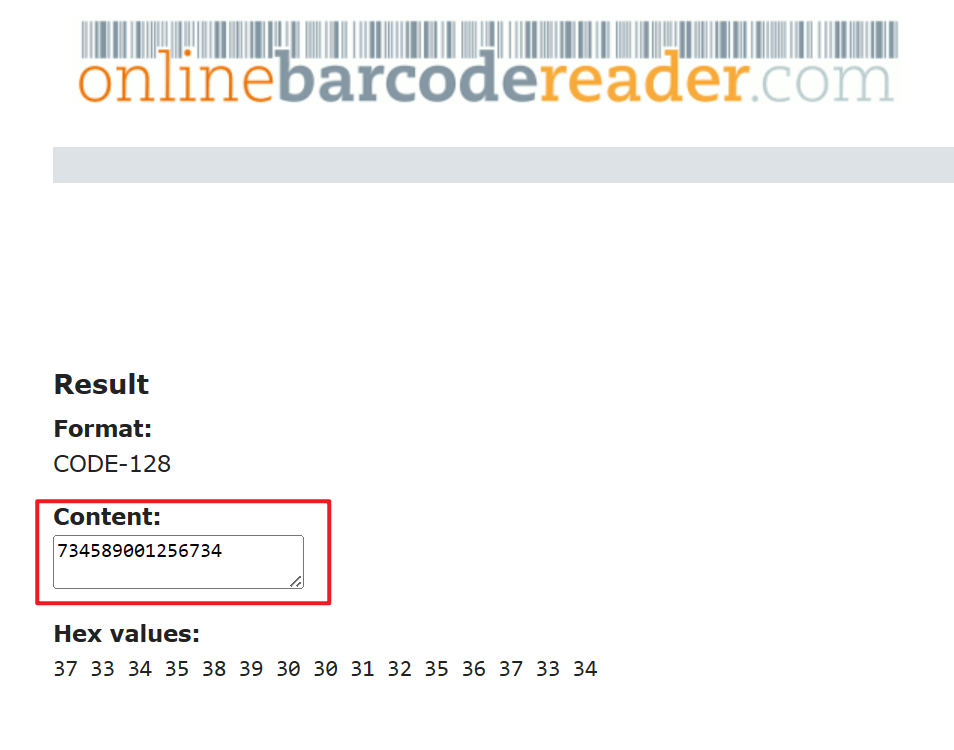
3、然後手動重新命名檔案即可。
方法三:使用 Python 腳本自動將 PDF 名稱更改為文件內條碼
推薦指數:★★☆☆☆
優點:
- 全自動批次處理,完全免費。
- 可以客製化各種需求。
缺點:
- 需要 Python 程式設計基礎,學習成本較高。
- Python 環境配置較為複雜。
操作步驟:
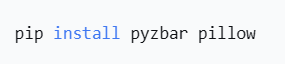
1、安裝 Python 和 Pyzbar 庫。
2、新建腳本 barcode_rename.py:
import os
from pyzbar.pyzbar import decode
from PIL import Image
import fitz # PyMuPDF
for pdf_file in os.listdir('.'):
if pdf_file.endswith('.pdf'):
# Extract barcode
doc = fitz.open(pdf_file)
page = doc[0]
pix = page.get_pixmap()
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
# Recognize barcode
barcodes = decode(image)
if barcodes:
new_name = barcodes[0].data.decode() + '.pdf'
os.rename(pdf_file, new_name)
3、最後執行腳本自動重新命名。