當多個txt文本裡存在相似但不完全一致的內容時,逐個打開檔案手動查找和替換,不僅耗時,還容易漏改。本文介紹如何使用辦公軟體「核爍文檔批量處理工具」,批量將txt中包含模糊關鍵字的整段內容替換成新的文字。文章會結合實際操作介面,說明適用場景、處理前後效果、具體步驟以及注意事項,幫助你快速完成文本清洗、內容統一、批量修訂等工作,減少重複勞動,提升檔案處理效率。
很多人在整理 TXT 文字檔 時,都會遇到這樣的問題:同一批文件裡有一些段落內容需要統一替換,但這些段落並不是完全一樣,只是都包含某些關鍵字或相似表達。如果一個個打開 txt 檔案、手動尋找、逐段刪除再貼上新內容,工作量大,還容易出錯。
本文要解決的就是這個場景:批量將 txt 中包含模糊關鍵字的段落替換成新的文字。結合截圖可以看到,我們使用的是辦公軟體 核爍文檔批量處理工具,它適合處理大量檔案,尤其適用於批量修改文字內容、統一資料格式、減少重複勞動。
適用場景
如果你有下面這些需求,這個方法就很適合:
- 批量清理多個 txt 檔案中的指定說明段、舊版本描述、無效內容;
- 按關鍵字定位整段內容,並統一替換成新的標準文字;
- 文字內容存在輕微差異,無法只靠「完全符合」尋找;
- 需要處理成批的記事本檔案、文字檔案,而不是只改一個檔案。
例如:一些 txt 文字中包含數字年份、固定短語或某段說明文字,只要命中這些關鍵字,就把對應整段替換成新的內容。這樣的處理方式,特別適合知識庫整理、採集文字清洗、批量校對、文案更新等辦公場景。
效果預覽
處理前
從範例截圖可以看出,原始 txt 檔案中有兩處需要處理的段落:
- 一處段落中包含類似 13.8 這樣的數字內容;
- 另一處段落中包含短語 In this sense。

這些內容位於各自所在的完整段落中,並不是只替換某個單詞,而是要把包含該關鍵字的整段內容整體替換掉。
處理後
處理完成後,原來命中關鍵字的整段內容被新文字替換。

範例中可以看到:
- 命中第一條規則的整段被替換為 testA;
- 命中第二條規則的整段被替換為 testB。
而沒有命中規則的其他段落,則保持原樣不變。這樣就能在不手動逐個編輯的情況下,快速完成批量替換。
操作步驟
第1步:進入文字工具中的對應功能
開啟 核爍文檔批量處理工具 後,在左側功能區選擇 文字工具。從功能列表中,點選 根據關鍵字尋找並替換文字檔案中的完整行。
從截圖可見,這個功能的說明就是針對文字檔案中的關鍵字進行整行或整段處理,正好對應本文需求:按關鍵字定位,再替換為新的文字。
這一步的目的:進入正確的批量處理模組。
預期結果:進入檔案匯入與處理配置介面。
第2步:批量添加需要處理的 TXT 檔案
進入功能頁面後,先在第 1 步「選擇需要處理的記錄」中匯入檔案。介面右上方可以看到以下按鈕:
- 添加檔案
- 從資料夾中匯入檔案
- 清空
- 更多
如果只是處理少量 txt 檔案,可以點選 添加檔案;如果要一次處理整個目錄下的文字檔案,直接使用 從資料夾中匯入檔案 會更高效。
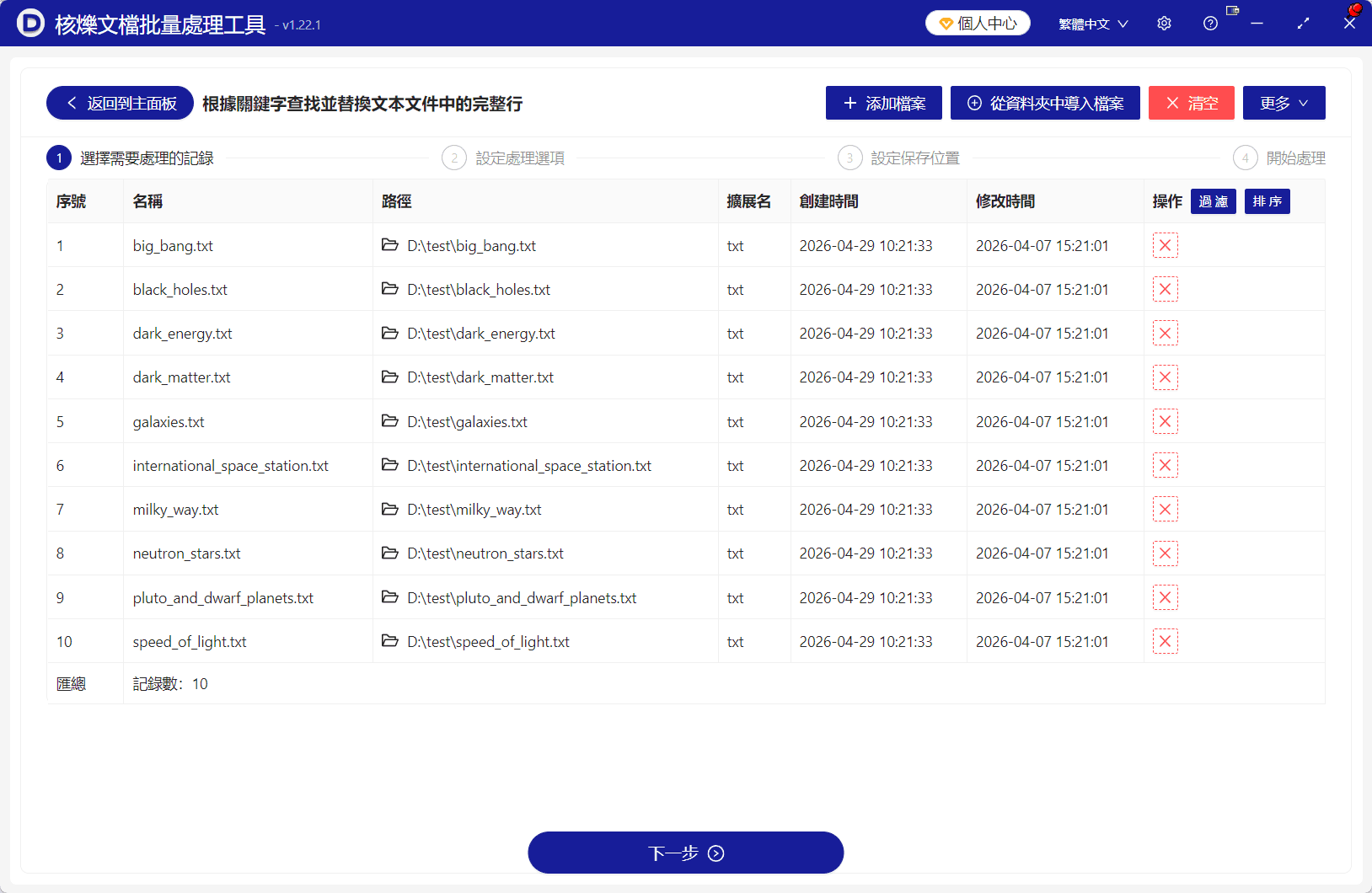
截圖中已經批量匯入了 10 個 txt 檔案,列表裡顯示了檔案名稱、路徑、副檔名、建立時間、修改時間等資訊,便於核對。
這一步的目的:一次性載入所有待處理的 txt 文字檔案。
預期結果:檔案列表中能看到已匯入的 txt 記錄,確認無誤後點選底部的 下一步。
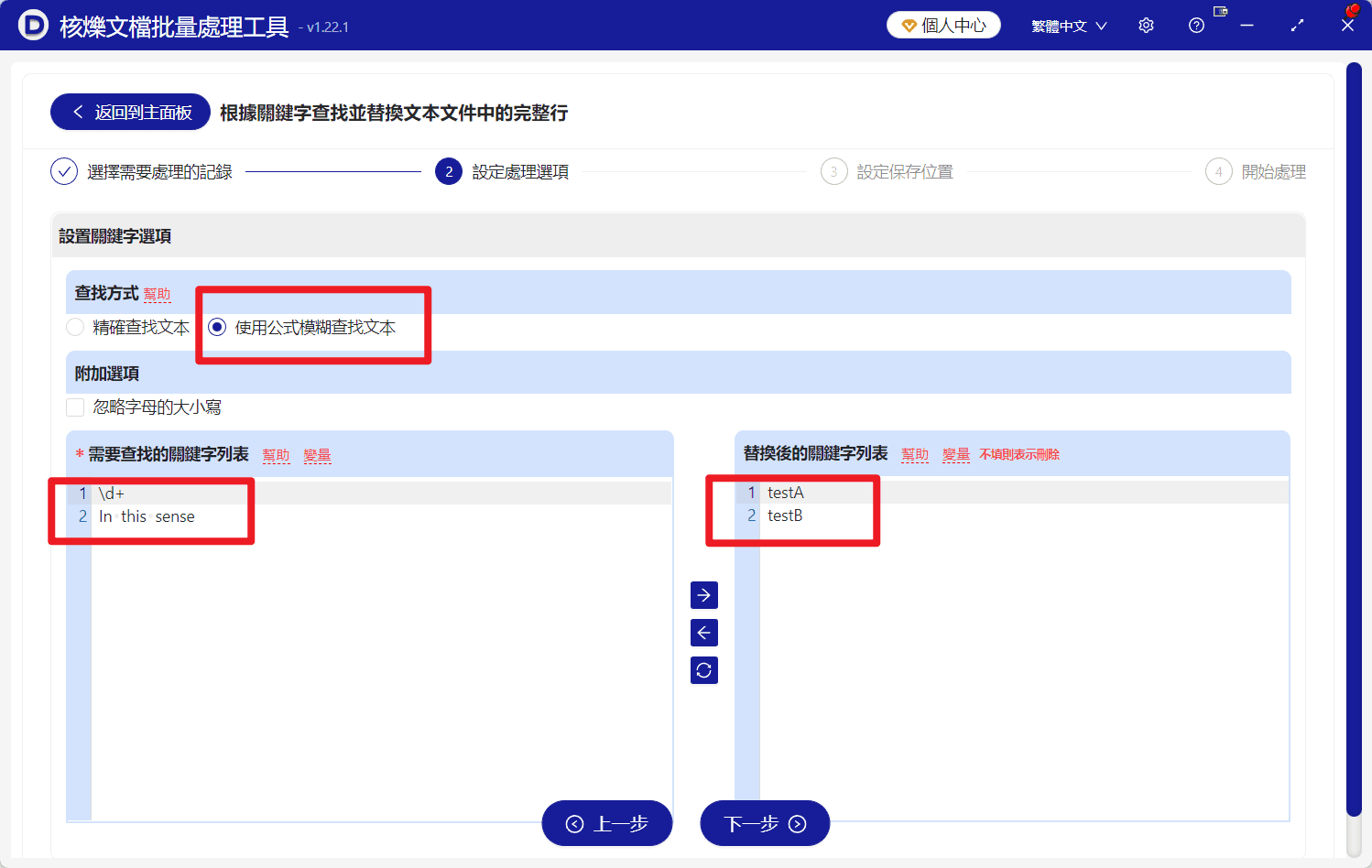
第3步:選擇模糊尋找方式
進入「設定處理選項」後,先設定尋找方式。截圖中可以明確看到,在「尋找方式」裡選擇的是:
使用公式模糊尋找文字
這一步非常關鍵。因為本文處理的是包含模糊關鍵字的段落替換,不是嚴格的一字不差尋找,所以應使用模糊尋找方式,而不是「精確尋找文字」。
另外,介面中還有「忽略字母的大小寫」選項。如果你的 txt 檔案中英文大小寫可能不統一,可以按實際情況考慮是否勾選。
這一步的目的:讓軟體按模糊規則識別內容,提高比對靈活度。
預期結果:系統將依據填寫的運算式或關鍵字規則進行尋找。
第4步:填寫需要尋找的關鍵字列表
在左側的 需要尋找的關鍵字列表 中,輸入要比對的內容。截圖範例裡填寫了兩條:
- \d+
- In this sense
從介面狀態來看,這裡支援按照模糊規則進行比對,因此既可以填寫固定短語,也可以填寫帶規則特徵的尋找內容。範例中的 \d+ 用於比對數字內容,In this sense 則用於比對包含該短語的段落。
這一步的目的:告訴軟體「哪些內容算命中目標段落」。
預期結果:軟體會在每個 txt 檔案中尋找包含這些關鍵字或規則的完整內容。
第5步:填寫替換後的新文字
在右側的 替換後的關鍵字列表 中,輸入對應的新文字。截圖中的兩條替換內容分別是:
- testA
- testB
這表示:
- 第一條尋找規則命中的完整內容,替換為 testA;
- 第二條尋找規則命中的完整內容,替換為 testB。
左右兩側列表是一一對應關係,因此填寫時要注意順序一致。
這一步的目的:為每條尋找規則指定替換結果。
預期結果:每個命中段落都能按對應規則替換成新的文字。
第6步:繼續下一步並執行批量處理
設定好尋找規則和替換內容後,點選頁面底部的 下一步,繼續後續流程。根據介面頂部步驟提示,接下來還會進入:
- 設定儲存位置
- 開始處理
也就是說,完成規則配置後,再設定處理結果的儲存位置,然後執行批量替換即可。
這一步的目的:提交處理規則並開始批量執行。
預期結果:軟體自動處理所有匯入的 txt 檔案,把包含模糊關鍵字的目標段落替換成你指定的新文字。
常見問題或注意事項
1. 模糊尋找和精確尋找有什麼區別?
如果你的目標內容在不同 txt 檔案中存在細微差異,或者你需要按某種模式比對內容,就應優先使用 使用公式模糊尋找文字。如果內容完全一致,才更適合使用精確尋找。
2. 尋找列表和替換列表的順序要一致嗎?
要一致。左側第 1 條對應右側第 1 條,左側第 2 條對應右側第 2 條。否則容易出現替換結果不符合預期的問題。
3. 這是替換單個詞,還是替換整段內容?
從截圖前後效果看,這裡處理的結果是:只要命中關鍵字,對應的完整段落內容會被新的文字替換。因此它適合做整段刪除、整段改寫、整段統一替換,而不只是簡單改一個詞。
4. 處理前要不要先備份檔案?
建議在正式批量處理前,先備份原始 txt 檔案,尤其是在規則較複雜、檔案數量較多時。先用少量樣本測試,確認結果正確後,再處理全部檔案,會更穩妥。
5. 能處理哪些文字檔案場景?
本文展示的是 txt 文字檔案批量替換場景,適合記事本檔案、純文字資料、批量匯出的文字內容整理等。若你還有 doc、docx、Excel、PDF 等文件處理需求,也可以結合這類辦公軟體中的其他模組繼續批量處理。
總結
對於「批量將 txt 中包含模糊關鍵字的段落替換成新的文字」這類需求,手動處理效率低、重複勞動多,而 核爍文檔批量處理工具 這類辦公軟體的優勢就在於:能夠把原本逐個打開、逐段尋找、逐段替換的工作,轉化為一次配置、批量完成。
實際操作中,你只需要:
- 進入文字工具中的對應功能;
- 批量匯入 txt 檔案;
- 選擇「使用公式模糊尋找文字」;
- 填寫尋找關鍵字列表和替換內容列表;
- 設定儲存位置並開始處理。
如果你經常需要批量整理文字、統一內容、清洗資料,建議直接把這個流程固定下來。先拿幾份樣本文本測試規則,確認無誤後再批量執行,能顯著減少重複勞動,提升檔案處理效率。