當一批 TXT 檔案中都含有相同結構的無用行時,逐個開啟刪除效率很低。本文透過核爍文檔批量處理工具演示如何匯入多個 txt 檔案,使用「使用公式模糊查找文字」輸入 Annex [A-Z] 這類萬用字元正則規則,並將取代內容留空,從而批次刪除所有包含目標關鍵字的完整行,適合文字清洗、日誌整理與資料歸檔。
在日常辦公中,TXT 文字檔常被用來保存目錄、日誌、資料匯出結果或系統產生的說明內容。它們輕量、易開啟,但也有一個常見問題:當檔案數量很多時,任何看似簡單的清理動作都會變成重複勞動。例如,多個文字檔中都包含 Annex A、Annex B、Annex C 這類附錄說明行,而你只想保留正文目錄和正文內容。如果逐個檔案開啟再刪除,不僅浪費時間,也容易因為疲勞操作造成漏刪或誤刪。
本文介紹一種更適合批次辦公的處理方法:使用核爍文檔批量處理工具,透過「根據關鍵字尋找並取代文字檔中的完整行」功能,配合萬用字元正則表達式批次刪除包含指定關鍵字的整行。它不是簡單取代某個詞,而是按照規則尋找一整行並刪除,因此特別適合處理目錄行、註釋行、日誌行、編號行等結構化文字。
下面會從適用場景、處理前後效果、軟體操作步驟和注意事項幾個方面展開,幫助你看完後就能自己完成 TXT 檔案批次清理。
適用場景:批次刪除文字檔中的規律性內容
如果你的文字檔中存在需要清理的固定格式內容,就可以考慮使用萬用字元正則。所謂固定格式,不一定是完全相同的文字,也可以是「開頭相同、後面變化」的內容。例如本文中的 Annex A、Annex B、Annex C、Annex D,雖然字母不同,但它們都符合 Annex 加空格加大寫字母的規律。
這種方法適合以下場景:
- 多個 txt 檔案中都有同類型的附錄行、說明行,需要批次刪除;
- 日誌檔案裡存在包含某個標識的記錄行,需要統一清理;
- 資料匯出檔案中有重複的表頭、註釋、頁碼行,需要移除;
- 文字資料中有類似 「Chapter 1」「Chapter 2」 或 「Annex A」「Annex B」 的規律行,需要按規則處理;
- 希望在不編寫腳本的情況下,用辦公軟體完成批次文字清洗。
核爍文檔批量處理工具屬於辦公軟體中的批次文件處理工具,它的價值不在於編輯單個檔案,而在於把同一個處理動作應用到多個檔案。對於經常處理 txt、文字資料、批次匯出內容的使用者來說,這類功能能明顯減少重複勞動。
效果預覽:批次處理前的檔案與內容狀態
處理前,範例資料夾中有 5 個 TXT 檔案,分別是 1.txt、2.txt、3.txt、4.txt、5.txt。這意味著本次不是單檔案編輯,而是對一組文字檔執行統一規則。

開啟 1.txt 後,可以看到檔案前部有 「Annexes」 標題,並在下面列出了 Annex A、Annex B、Annex C、Annex D 等內容。這些行後面還帶有不同說明文字,例如 「Food and drink standards - revised 2020」「The secondary school analysed meal」等。紅框標出的 Annex A 到 Annex D 就是本次需要刪除的目標行。
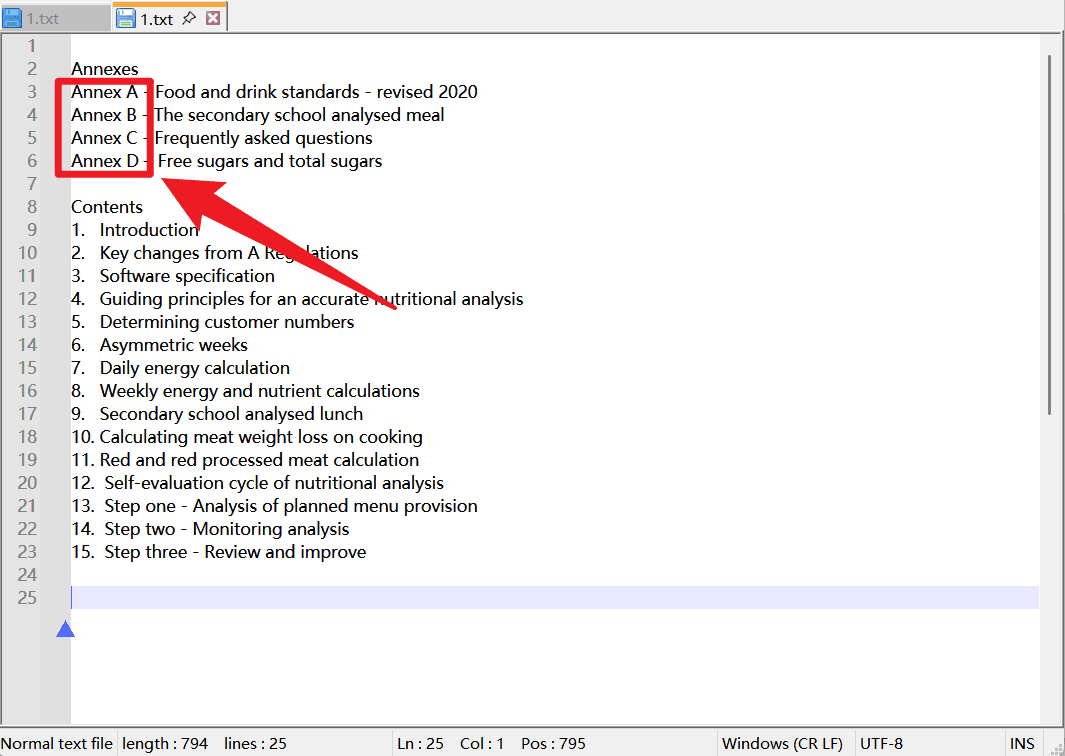
如果只用普通尋找取代,你可能需要分別處理 Annex A、Annex B、Annex C、Annex D,甚至更多字母。這樣規則數量會增多,也不利於後續複用。更合理的方式是用一個表達式概括這些內容,例如 Annex [A-Z],讓軟體自動識別從 Annex A 到 Annex Z 的同類行。
效果預覽:處理後目標整行被刪除
完成批次處理後,再查看產生的文字檔,可以看到原來的 Annex A、Annex B、Annex C、Annex D 行已經消失。檔案頂部保留了 「Annexes」,後面直接進入 Contents 和具體目錄項目。紅框位置顯示目標區域已經被清理。
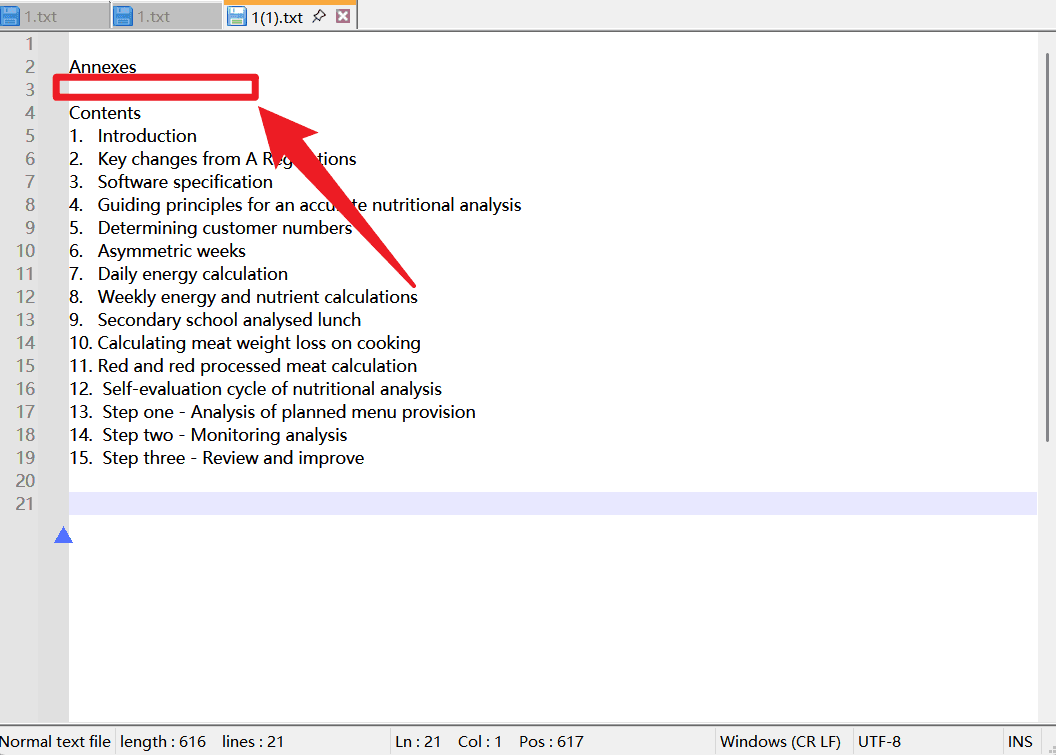
這種處理結果說明,軟體並不是只刪除了 「Annex A」 這幾個字元,而是刪除了包含匹配內容的完整行。對於批次清理文字來說,這一點很關鍵。如果只刪除關鍵字,後面的說明文字可能還會殘留;刪除完整行則能讓無用記錄徹底消失。
操作步驟:從匯入檔案到設定正則刪除規則
步驟一:在文字工具中找到對應功能
啟動核爍文檔批量處理工具後,左側可以看到多個工具分類,包括 Word 工具、Excel 工具、PowerPoint 工具、PDF 工具、文字工具等。由於本次處理的是 TXT 文字檔,因此需要選擇「文字工具」。
在文字工具頁面中,選擇「根據關鍵字尋找並取代文字檔中的完整行」。從截圖提示可以看出,這個功能用於批次將文字檔中包含某個關鍵字的整行刪除或者取代成新的文字。
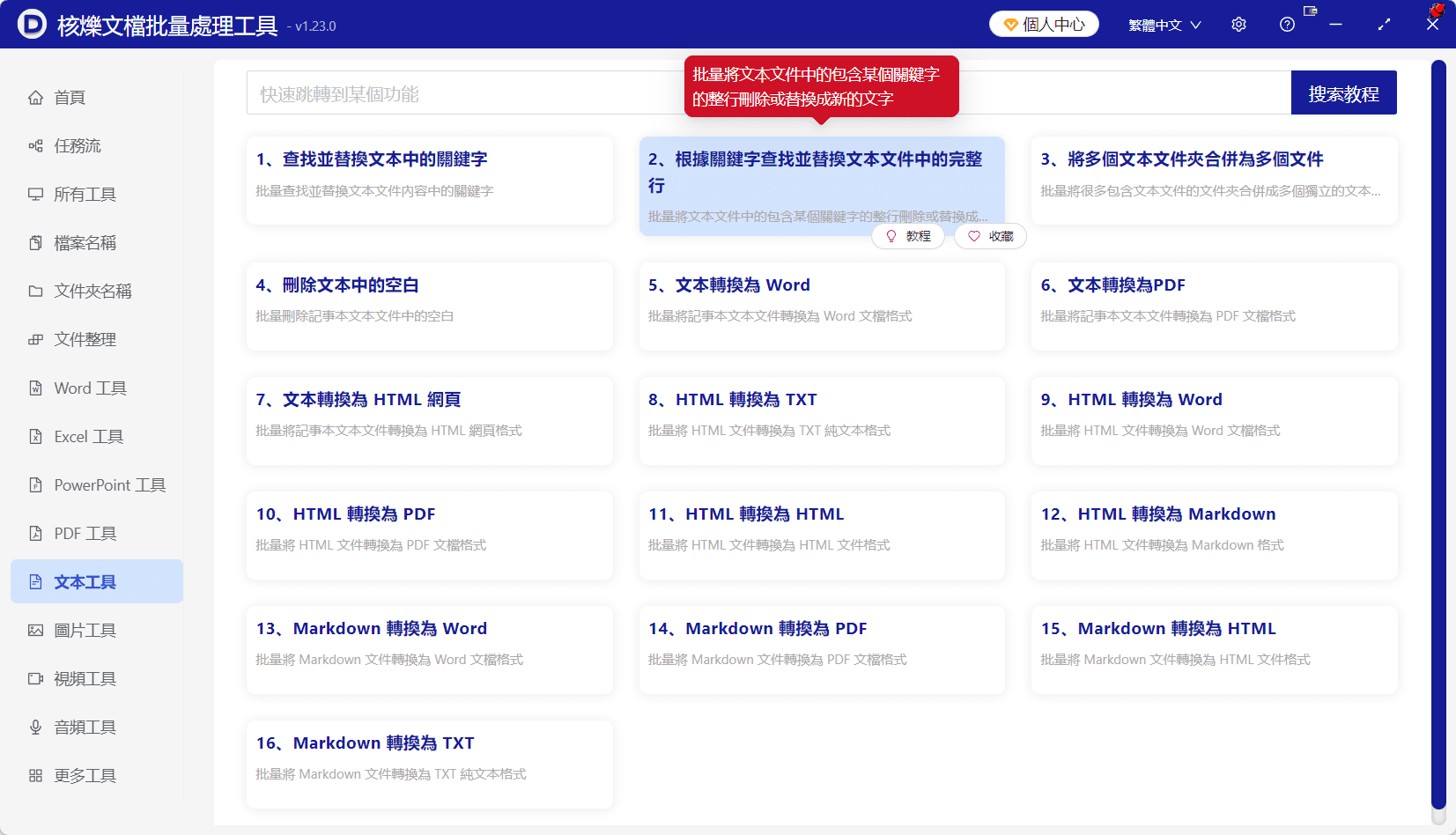
選擇這個功能的原因很簡單:我們要刪除的是整行,而不是只刪除某個詞。功能名稱中的「完整行」正好對應需求。
步驟二:匯入要批次處理的 txt 檔案
進入功能頁面後,第一步是「選擇需要處理的記錄」。介面右上方提供「加入檔案」和「從資料夾中匯入檔案」等入口。對於少量檔案,可以直接加入檔案;對於同一資料夾下的大量 txt 檔案,更適合使用從資料夾匯入的方式。
範例中已經匯入了 5 個文字檔,列表顯示了檔案名、路徑、副檔名、建立時間、修改時間等資訊。這裡可以看到檔案路徑位於 D:\test\,副檔名都是 txt。
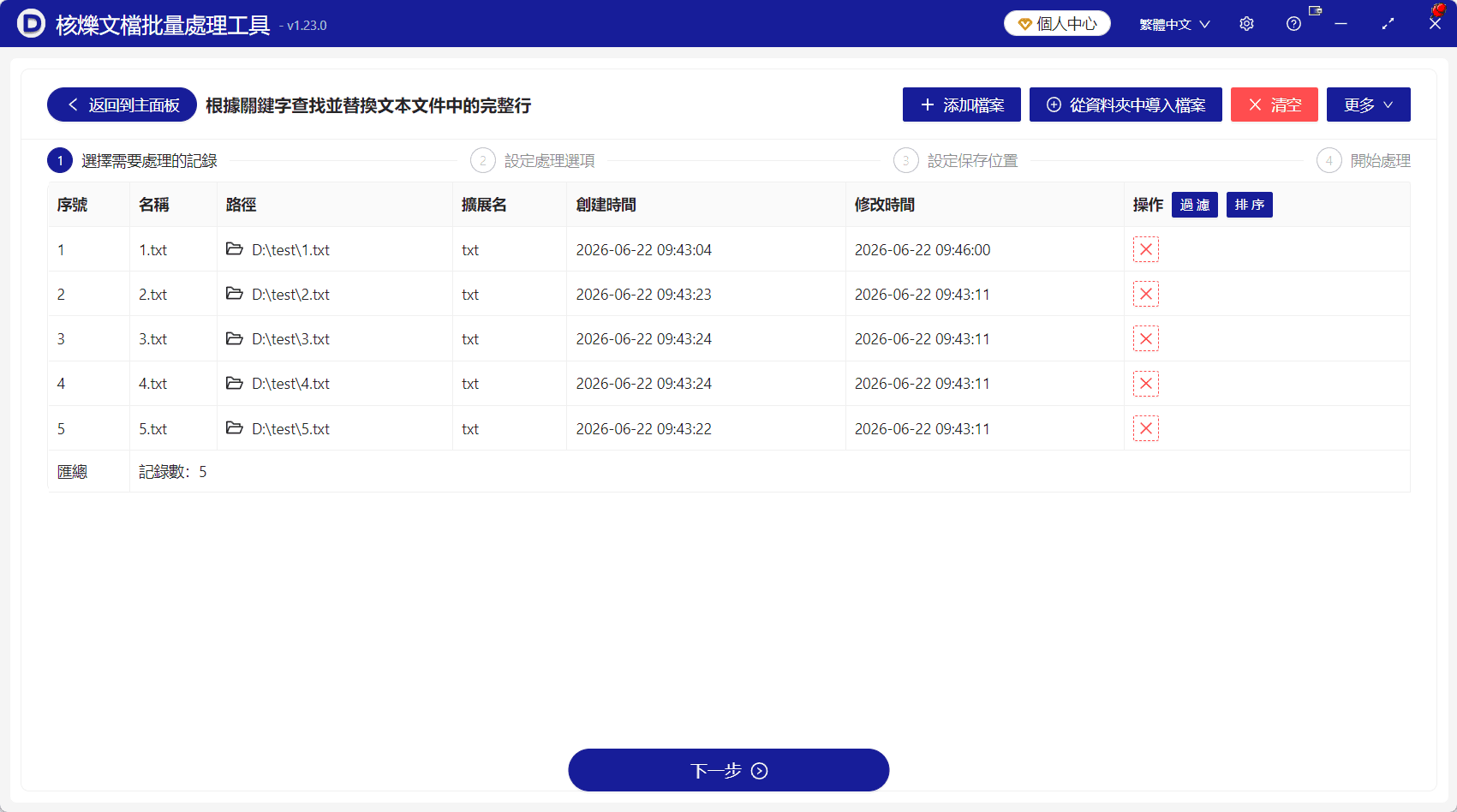
匯入後不要急著下一步,建議先檢查三個資訊:第一,檔案數量是否正確;第二,檔案副檔名是否都是要處理的 txt;第三,路徑是否為目標目錄。確認無誤後,點擊底部「下一步」。
步驟三:設定查找方式為公式模糊查找
進入「設定處理選項」後,需要先確定查找方式。截圖中選擇的是「使用公式模糊查找文字」。這個選項適合使用萬用字元、範圍表達式或類似正則的規則來匹配文字。
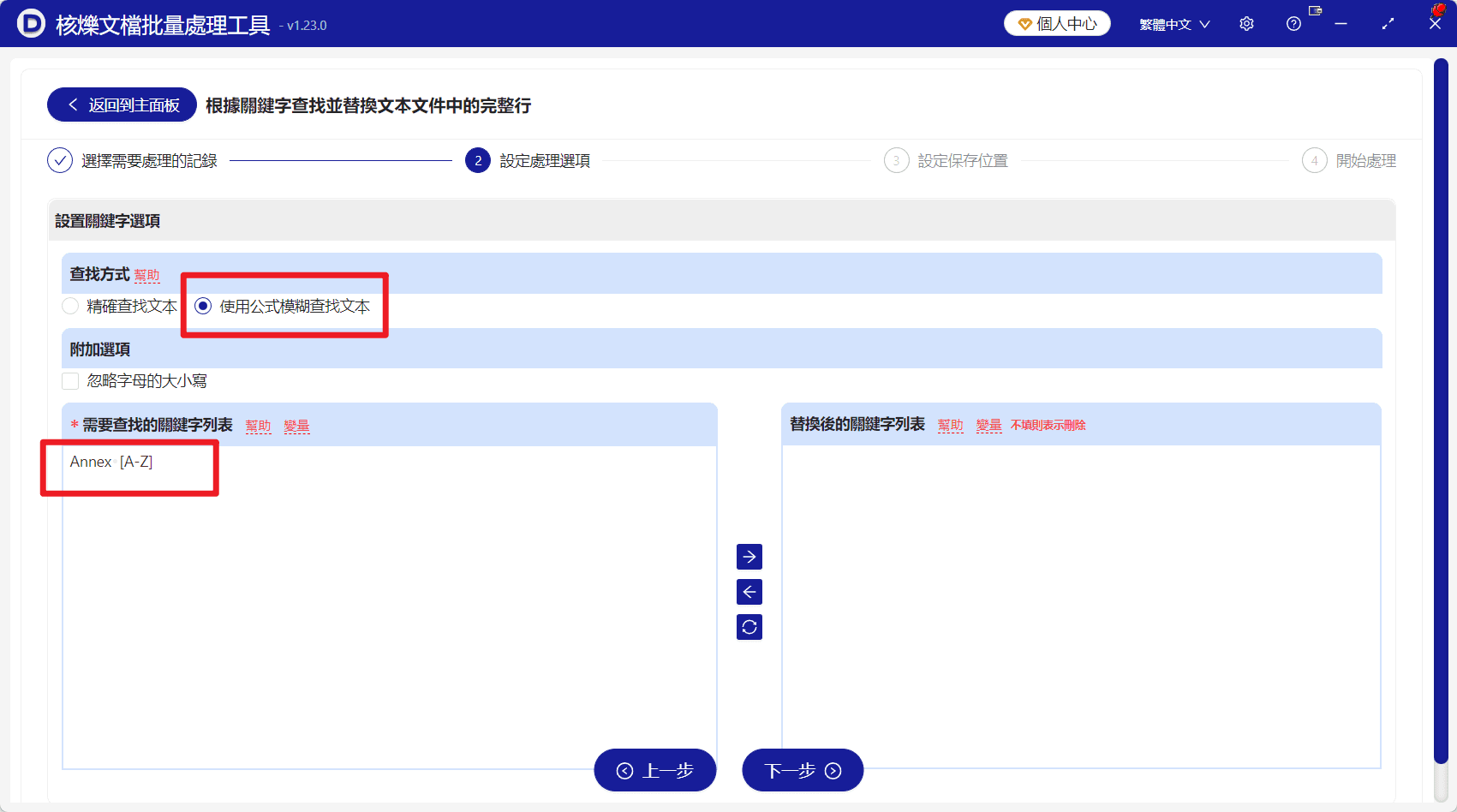
如果選擇普通的精確查找,通常只能匹配固定文字;而 Annex A、Annex B、Annex C 這類內容雖然相似,但並不完全相同。使用公式模糊查找後,就可以用一個規則涵蓋多個變體。
步驟四:在關鍵字列表中輸入 Annex [A-Z]
在左側「需要尋找的關鍵字列表」中輸入:
Annex [A-Z]
這個表達式的作用是匹配 Annex 後跟一個大寫字母的文字。範例中的 Annex A、Annex B、Annex C、Annex D 都符合這個規則。由於本功能處理的是包含關鍵字的完整行,所以這些行會被整體識別為待處理行。
在實際使用時,你也可以根據自己的檔案內容調整表達式。例如,如果要匹配編號行,可以設計與編號規律相符的表達式;如果要匹配固定首碼行,可以將固定首碼寫入關鍵字列表。但本文不展開其他規則,重點是掌握「用一個表達式匹配一組類似行」的思路。
步驟五:取代內容留空,實現刪除整行
右側區域是「取代後的關鍵字列表」。截圖中該區域為空,並且介面上有提示「不填則表示刪除」。因此,如果你的目標是刪除匹配整行,就保持右側為空,不要輸入空格、符號或其他文字。
這一點非常重要。留空表示刪除;如果輸入了其他內容,處理結果就會變成把目標行取代成指定文字,而不是移除。確認左側表達式和右側空白狀態後,繼續點擊「下一步」。
步驟六:設定儲存位置並開始處理
根據頁面頂部流程,後續步驟為「設定儲存位置」和「開始處理」。儲存位置用於指定處理後檔案輸出到哪裡。批次刪除屬於不可忽視的內容變更,建議將結果儲存到新位置,便於與原檔案對比。
完成儲存位置設定後進入開始處理階段,軟體會按照匯入列表逐個處理檔案。處理完成後,開啟輸出檔案檢查是否如預期刪除了 Annex 行。如果結果正確,就可以把同樣方法應用到更多 TXT 檔案中。
常見問題與注意事項
1. 表達式是否區分大小寫?
截圖中的附加選項裡有「忽略字母的大小寫」。如果你的檔案裡可能同時出現 Annex A、annex A 或 ANNEX A,可以根據需要勾選該選項。本文範例中目標內容是標準大寫形式,因此沒有特別依賴該選項。
2. 為什麼處理後還保留了空行?
從處理後截圖看,Annexes 和 Contents 之間保留了一行空白。這通常與原文字結構和刪除行後的換行有關。本文重點是刪除包含匹配內容的整行,是否進一步刪除空白行,可以根據實際整理要求再處理。
3. 能否一次輸入多個查找規則?
介面上是「需要尋找的關鍵字列表」,說明可以按列表方式管理查找項目。實際操作時,如果有多類不同規則,可以分別填寫。但建議先從一個規則開始測試,確認輸出正確後再增加規則,避免匹配範圍過大。
4. 處理前是否需要備份?
建議保留原檔案或將結果輸出到新資料夾。批次處理最大的優勢是快,但也意味著錯誤規則會快速影響多個檔案。先備份、再測試、最後批次執行,是更穩妥的辦公流程。
總結:用規則化批次處理提高文字清理效率
本文示範了如何使用核爍文檔批量處理工具批次刪除 TXT 檔案中包含指定關鍵字的整行。核心流程是:進入文字工具,選擇「根據關鍵字尋找並取代文字檔中的完整行」,匯入多個 txt 檔案,選擇「使用公式模糊查找文字」,輸入 Annex [A-Z],並將取代內容留空,最後設定儲存位置並開始處理。
相比手動編輯,這種方法更適合大量檔案、重複內容和規則化文字清理。只要目標行有明確規律,就可以用萬用字元正則表達式把重複勞動交給辦公軟體完成。建議你在處理大批量檔案前,先選幾個樣本測試規則,確認無誤後再批次執行,從而兼顧效率和安全性。